
 CA
CA
Activity
Ratings Progression
Challenge Categories
Challenges Entered

Reinforcement Learning on Musculoskeletal Models
Latest submissions

Disentanglement: from simulation to real-world
Latest submissions
See All| graded | 24215 | ||
| graded | 21040 | ||
| graded | 21036 |
| Participant | Rating |
|---|
| Participant | Rating |
|---|
NeurIPS 2019 : Disentanglement Challenge

Thanking the organizers
Over 4 years agoWell said @moksh_jain
I, as well, want to thank the organizers, especially the many who took time out of their busy schedule to oversee the well-being of this challenge.
Great design, Cool dataset, One-of-a-kind experience!
All submissions are rejected with no slots available
Over 4 years agoAll my submissions are rejected with the following error:
"Submission failed : The participant has no submission slots remaining for today."
My last evaluated submission was 40 hours ago.
Potential issue with choosing the best submission of each participant
Over 4 years agoPlease check these two submissions:
#15813: ranks = 6,4,4,2,4 (average=4.0)
#15919: ranks = 2,4,4,4,4 (average=3.6)
However, it seems that #15813 is chosen as my best on the public leaderboard of round 2.
Please let me know of you thoughts,
Thanks
Leaderboard of Round1 and Private Leader Boards
Over 4 years agoLeaderboard of Round1 and Private Leader Boards are inaccessible.
[Announcement] Start of Round-2
Over 4 years agoThanks @mohanty
Please let us know of the reports/papers once they became available.
[Announcement] Start of Round-2
Over 4 years agoThank you @mohanty
We select the model with the highest average rank across all metrics on the leaderboard and call it the selected model.
I recall we were asked to nominate one of our submissions as the one we assume to be the best. I wonder which path the committee ended up taking: choosing the best model automatically, or based on the user’s selection.
[Announcement] Start of Round-2
Over 4 years agoSo I guess this is the final results: https://www.aicrowd.com/challenges/neurips-2019-disentanglement-challenge/leaderboards?challenge_round_id=73
Is the ranking algorithm as was discussed: average of the rank of each metric for each participant?
If so, I guess I missed by 1 rank to be among the top 3 
[Announcement] Start of Round-2
Over 4 years agoThank you for the announcement.
Where can we check the final results for stage 1 and it’s reposts?
The competition is halted?
Over 4 years agoThere seems to be no progress in the competition and the results of the first stage are not yet out. Please advise us on whether to start contributing to the second stage.
Thanks.
Mismatch of Report Submission time; openreview closed before scheduled!
Over 4 years agoThe deadline for the submission of the report is set to “August 16th, 2019, 11:59pm AoE: Submission deadline for reports, Stage 1” in here: https://www.aicrowd.com/challenges/neurips-2019-disentanglement-challenge#timeline
There is still 24 hours left for the submission, however, the openreview portal seems to have closed the submissions and I can’t update my stub to the finalized report!
[Announcement] Leaderboard Computation
Over 4 years ago@mohany
I want to propose an alternative approach for your consideration:
You can normalize each metric by dividing its value by the maximum value of that metric achieved across all the participants (i.e. only one participant is likely to get 1.0 out of 1.0 for each metric).
Once the above is done, simply sum over all metrics of a submission and rank accordingly.
[Announcement] Leaderboard Computation
Over 4 years ago@mohanty
I believe there is a flaw with the suggested ranking system. I sent you an email where I have highlighted the potential issue and a possible fix.
Thanks.
Stage one extended?
Over 4 years ago(topic withdrawn by author, will be automatically deleted in 24 hours unless flagged)
Resource restrictions for training the submissions
Almost 5 years agoPlease make sure that only the “training and evaluation” time is counted towards the 8 hours, and not the following:
- build time,
- time waited in queues to initialize either training or evlauation
Thanks.
Failed builds are being considered in the daily submission limit
Almost 5 years agoThank you for the response, and it makes sense.
However, I can see scenarios where you distinguish between fails like the attached screenshot here, and other runs which failed after training initiated successfully and the user received some feedback:
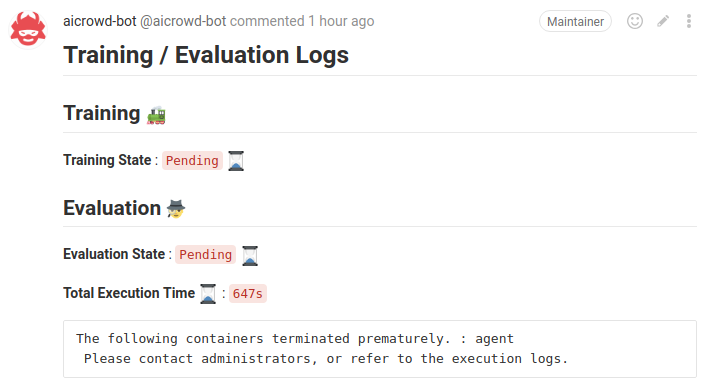
Simply put, I don’t see the users getting any feedback/information back unless the training is complete, thus, it seems safe not to include failed builds and failed trainings in the total number of submissions.
Pytorch fail during the evaluation
Almost 5 years ago@mohanty
I still have issues.
That successful submission was just me submitting the base to make sure the backend is actually functional.
I guess some debug logs would help; at this point, I have no idea what could be the problem without some feedback on your side.
As a side note, it would be nice if “failed submissions” were not counted towards the maximum daily allowed submissions.
Thank you for the response.
Pytorch fail during the evaluation
Almost 5 years ago@Jie-Qiao
Did you ever find out why this problem is occuring?
My evaluations are still failing and everything seems to be in place.
I have tagged @mohanty to give me access to the debug logs to figure out the reason; no answers yet after 2 days.
Failed builds are being considered in the daily submission limit
Almost 5 years agoIt would have been nice if only graded submissions were considered in the daily limit.
Thanking the organizers
Over 4 years agoWas there any final results announcement for any of the competition streams? Not sure. Maybe on Twitter?