
Organization
Location
 Singapore, SG
Singapore, SG
Badges
Activity
Ratings Progression
Challenge Categories
Challenges Entered

Revolutionising Interior Design with AI
Latest submissions

Understand semantic segmentation and monocular depth estimation from downward-facing drone images
Latest submissions

Audio Source Separation using AI
Latest submissions

3D Seismic Image Interpretation by Machine Learning
Latest submissions
See All| graded | 109741 | ||
| graded | 109708 | ||
| graded | 109644 |

Play in a realistic insurance market, compete for profit!
Latest submissions

Multi-Agent Reinforcement Learning on Trains
Latest submissions

Predicting smell of molecular compounds
Latest submissions
See All| graded | 82482 | ||
| graded | 82418 | ||
| graded | 82417 |

Find all the aircraft!
Latest submissions


5 PROBLEMS 3 WEEKS. CAN YOU SOLVE THEM ALL?
Latest submissions
See All| graded | 109741 | ||
| graded | 109708 | ||
| graded | 109644 |

Latest submissions

Recognizing bird sounds in monophone soundscapes
Latest submissions

Multi-Agent Reinforcement Learning on Trains
Latest submissions

Perform semantic segmentation on aerial images from monocular downward-facing drone
Latest submissions
| Participant | Rating |
|---|
| Participant | Rating |
|---|
Generative Interior Design Challenge 2024
SUADD'23- Scene Understanding for Autonomous Drone

Is joint semantic segmentation and depth prediction accepted as solution?
About 1 year agomulti-task model can help to improve model accuracy when there is few data.
some papers show good results for joint semantic segmentation and depth prediction task.
is this a valid solution for Scene Understanding for Autonomous Drone SUADD 2023?
Note: this will use both depth and label data for each competition.
can we use depth data to generate novel view synthesis for segmentation training? (e.g. can we cross use the data of different task?)
Semantic Segmentation
Requirenment: inference time on g4dn.xlarge limited to 10s per image
About 1 year ago(topic deleted by author)
Seismic Facies Identification Challenge
Hand labeling
Over 3 years agoI have a slightly different but related question. Round two is based on test set 2.
Now we have test set 1. are we allowed to hand label test set 1 (since it is not used in the evaluation of round 2)?
Ground truth annotation error
Over 3 years agoannotation error
I wonder does this affects evaluation results and should I include this error in my submission?

Learning to Smell
Can we use third party data?
Over 3 years agothere are lots of them. “goodscentscompany.com” is only one of them. But note that the label is different for the same chemical molecule in this challenge.
What is the cause of ambiguity of structure and odor label
Over 3 years ago“Chemical features mining provides new descriptive structure-odor relationships”-Carmen C. Licon
(https://journals.plos.org/ploscompbiol/article/file?id=10.1371/journal.pcbi.1006945&type=printable)
" Predicting natural language descriptions of smells"- Darío Gutiérrez
(https://www.biorxiv.org/content/10.1101/331470v1.full)
“Molecular complexity determines the number of olfactory notes and the
pleasantness of smells” - Kermen F
(https://www.nature.com/articles/srep00206.pdf)
What is the cause of ambiguity of structure and odor label
Over 3 years ago
some more interesting poster here: https://www.compoundchem.com/category/aroma-chemistry/
What is the cause of ambiguity of structure and odor label
Over 3 years agocheck these as well:
Theories of Smell: Part IV - Molecular Shape Theories of Smell

other videos the playlist: https://www.youtube.com/watch?v=uzJaRAsey-8&list=PLckhtk7WxsVZonou4vr8DrK8M3QFaF_IB
can’t image that small is also related to Quantum Mechanics (vibrating molecule)
What is the cause of ambiguity of structure and odor label
Over 3 years agoHere are some diagrams from the google paper: “Machine Learning for Scent: Learning Generalizable
Perceptual Representations of Small Molecules”
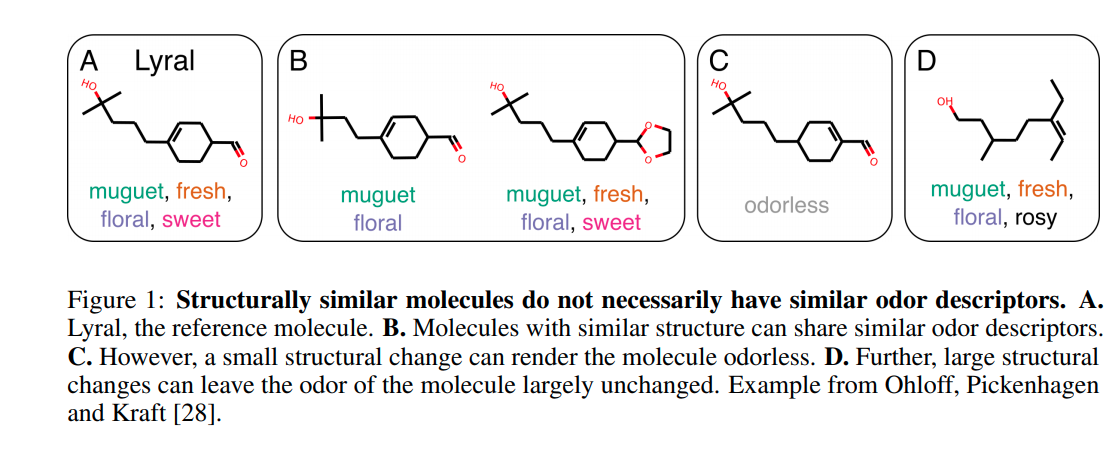
especially in figure 1 “Structurally similar molecules do not necessarily have similar odor descriptors.”
why is this so? is it because 3d information is not used (molecule are essentially 3-dimensional)
i have develop a basic graph CNN and now thinking of how to improve results. If structure cannot tells the odor, what else do?
Thanks!
"AssertionError: Unknown smell words provided in the predictions file"
Over 3 years ago# df has the columns 'SMILES', 'SENTENCE','PREDICTIONS'
# LABEL_COL is the word list= read from vocabulary.txt
def check_df_error(df):
predict = df['PREDICTIONS'].values
word = set()
for p in predict:
p = p.replace(';',',').split(',')
p = set(p)
word = word.union(p)
label = set(LABEL_COL)
diff = label.symmetric_difference(word)
#print('diff',diff) #word not used in prediction all all
print('diff:',diff-label.intersection(diff)) #word not found in LABEL_COL at all
i suspect you have a ‘’ entry (i.e. empty string).
Note that in your code if split returns empty list, it will not do any checking all all! this can happen if you have bug or forget to insert ‘,’ or ‘;’ in your prediction
Questions about evaluation metric
Over 3 years agocurrently in round one, we are asked to predict 1 to 3 tags per sentence.
we can predict up to 5 sentence.
External solution using using Graph Neural Networks (GNNs)
Over 3 years agothere is one paper that further uses NLP to analyse the distance of the tag in the ground truth … e.g. what is the similarity between scent “rose” and “flower”, etc … sometimes such description are subjective. so the paper see if we can better results by processing the label, e.g. clustering/hierarchy, etc
Question about test images and prompt
2 months agoThanks for setting up this competition. I suppose one approach is to fine tune controlnet for better score given the performance metrics. i have question about the test images and prompts.
“You will be provided a total of 1800 seconds to run the complete private set of images containing 40 images. Your models also need to”
I suppose there is only one prompt per images?
(i.e. only 40 test samples)
i also want to confirm the public leaderboard results is only based on public 3 images only.
on a side note, it might be better to provide a few more examples of prompt or at least some keywords, or some references (paper, other public datasets, blogs, etc). We do not know how big is the scope of the objects, style, descriptions in the prompt.
some open dataset:
Controlnet for Interior Design - a Hugging Face Space by ml6team
(GitHub - ml6team/fondant-usecase-controlnet: Example Fondant pipeline preparing data to train a Controlnet model)
Interior design with stable diffusion