Learning RL through competitive games: AIcrowd’s DroneRL Workshop
 By
snehananavati
By
snehananavati
Reinforcement Learning is one of the fastest-growing paradigms in the field of machine learning. Much like supervised and unsupervised learning, RL requires going through stacks of theoretical knowledge and hours of execution. In short, learning RL can be complicated.
So to counter this, AIcrowd conducted DroneRL, a workshop that fast-tracks knowledge of RL through hands-on problem-solving.
Keep reading as we share the winners' experiences and some helpful notebooks and resources to get you started on your RL journey!

The workshop at AMLD was organized in collaboration with the EPFL Extension School. A full-day event, DroneRL, was divided into two 4-hour sessions. The audience was a mix of experienced machine learning professionals and curious computer science engineers. Our aim was to introduce advanced RL concepts to an audience of beginners. Keeping in mind that most of the participants were new to this domain, we focused on designing a problem that was interesting while also being simple enough that individuals with some basic ML knowledge were able to get some results.

Introduction to Reinforcement Learning
We introduced the foundational concepts of RL in a phased manner - striking a balance between providing theory and implementation. Notebooks on Google Collab, prepared by our team at AIcrowd, were popular among the participants as it provided them with an easy starting point. The foundational RL theory was introduced through slides and all participants were provided with Notebook on the Delivery Drone Environment. This approach helped several novice participants to run codes and develop an intuition on how to train an agent efficiently by observing the interplay between various hyperparameters. The participants who topped the scoreboard developed a neat strategy! They began training early in the challenge towards achieving one solution.
Conversation with the winners
We sat down with Cedric Bleuler , a member of the winning team, Zuehlke , to know more about his experience and approach. Cedric describes the workshop to be " great in terms of expectation management ,". Adding: “ Often when people introduce the topics like RL, [they] would tell you how amazing it is, and you can do everything with it, even though it's not true. With the setup of notebooks and starter codes, you could apply the theory into practice immediately, and you could play around with different network architectures. You did not lose any time with setup and the whole overhead you have with such a problem. That was well done, and other workshops did not manage to do it as well. "
Cedric echoed the benefit of a well-design challenge by adding, " you could really see the drones flying around, it's not just a number." Of course, the people there are data scientists and AI experts and but still, gamification works well with all kinds of people. "


Cedric completed a Bachelor’s in Mathematics at EPFL. He, then, did a Master’s degree in Applied Mathematics at ETH in Zurich, with a strong focus on Statistics and Machine Learning. He is currently working as a Data Scientist, providing ML solutions to customer projects. While experienced in Machine Learning, Cedric was a novice to the field of RL before this workshop. Sharing his experience, he said, “While I wouldn’t recommend this workshop to complete beginners in Machine Learning, I would recommend this to newcomers in Reinforcement Learning.”
How to get started with RL problem according to our winner
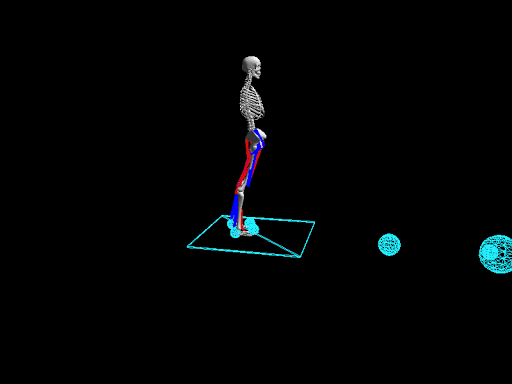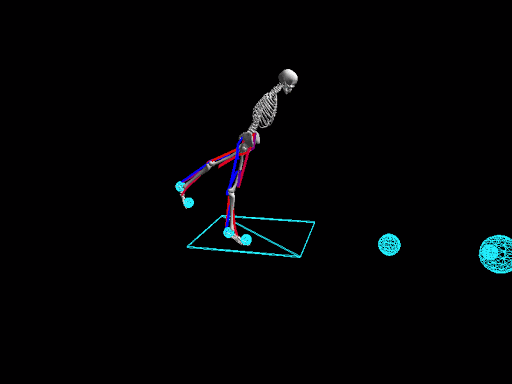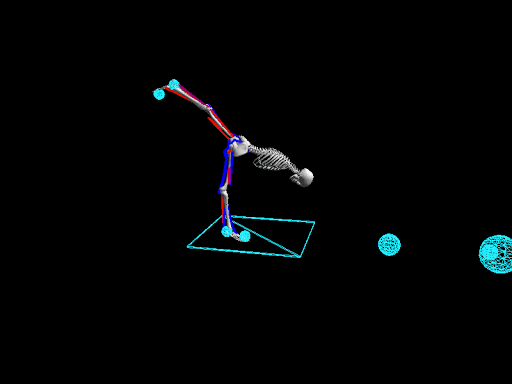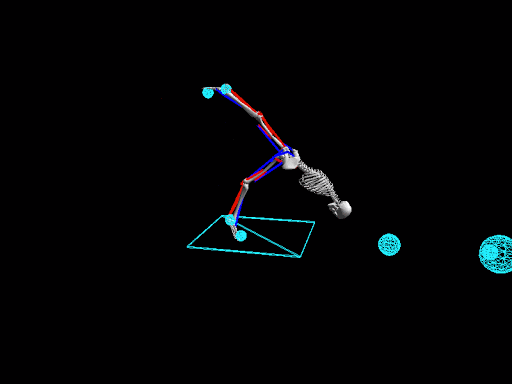


Elaborating on his thoughts on RL, he adds, " The development process of RL is quite a long one." When you have a classic supervised case, it's quite easy to set up a pipeline and to validate models at a fast pace. Whereas with Reinforcement Learning, the models need to be developed by themselves and which makes it a lot harder and time-intensive. "
Describing the benefits of the infrastructure of the competition, Cedric said, “ Since it was a Neural Network, it was just an intuition to make the thing a little wider. I think it was doubling or tripling the width of the network. Then it also came down to quite a bit of training; we tended to train for quite some time since it was improving. Then it was also a little bit down to luck, I guess, that we just bet on the right horse and let it run long enough to be good enough. We were playing around with the width of the network. After revamping the servers, it was like - whoa okay - this works ! " This method of spending more time on a more straightforward approach gave better results than what is often observed in conventional reinforcement learning problems.

Cedric, while sharing his feedback on the format of the workshop said, " ... we found the amalgamation of learning and implementation to be ideal," as it allowed them to try out the principles they learnt. On being asked if the constraints in submission felt restrictive, Cedric said, “ I did not feel limited because it was enough for the time frame. If we had more time, say a day or two, then yes, I would have liked to try out a little bit more different network styles. Then the limitations would have been annoying, but in that time frame, I did not feel limited, because I did not have the time to go beyond what was already proposed to me. "
We asked Cedric if he found AIcrowd to be a platform suited for amateurs in ML and if he would participate in challenges again. Cedric replied, " Yes, absolutely !". He goes on: "I think for the use case, it's well designed, it's scalable, as you proved during the competition ."
Here are some cool challenges to get you started on your RL journey!
Here at AIcrowd, we aim to build a machine learning community that caters to novices and veterans alike. We are constantly running various ML challenges to encourage and encourageivize beginners. If you're interested in learning RL, you can check out our MineRL challenge which is part of NeurIPS 2020 competition. Get started with these baselines created by the Preferred networks team and start finding the diamonds!

If you like to use RL to solve real-world problems, you'll enjoy our Flatland challenge , a multiagent reinforcement learning challenge on train schedules. (Also a part of NeurIPS 2020 competition). Your contribution may shape the way modern traffic management systems are implemented! With our dedicated challenge discussion page , you'll always have a helping hand to get you started. :)
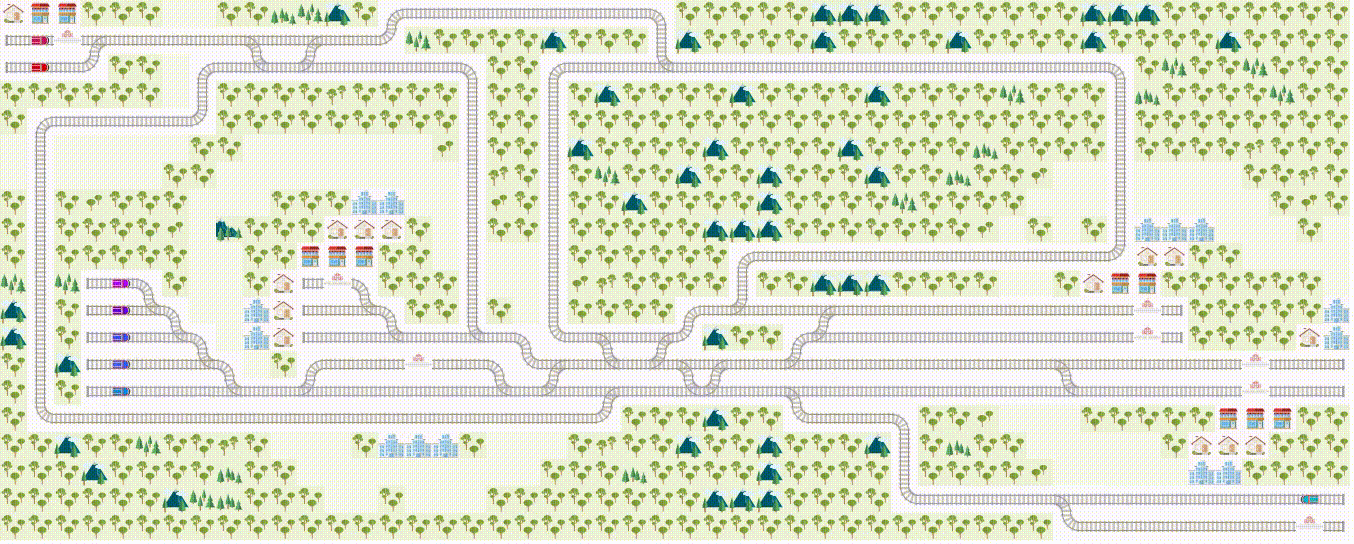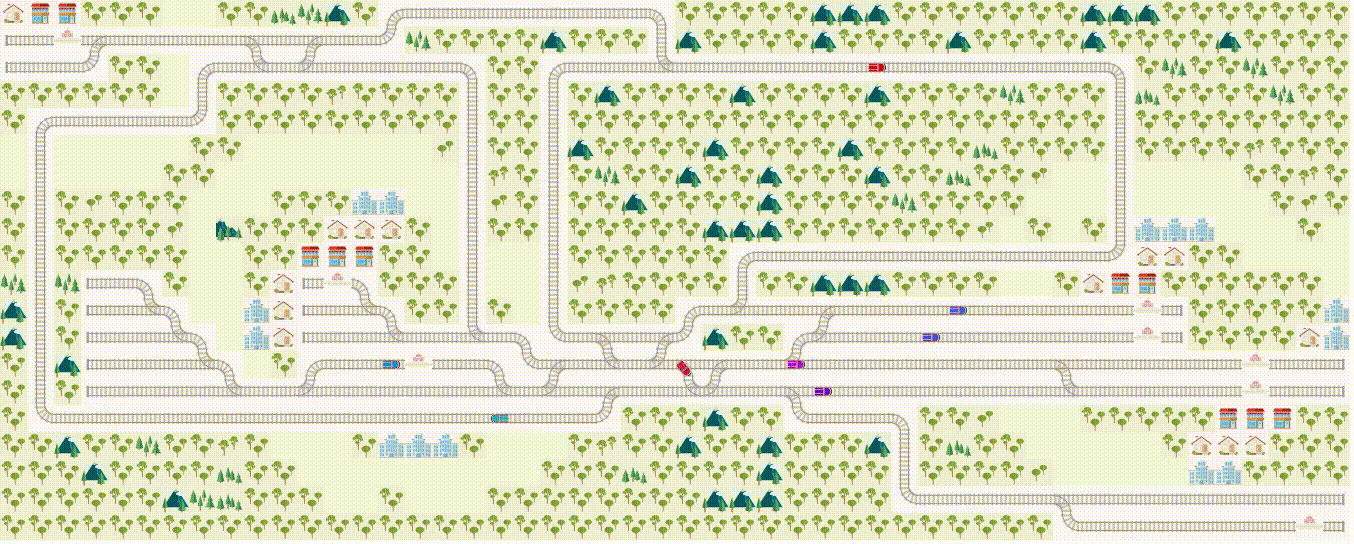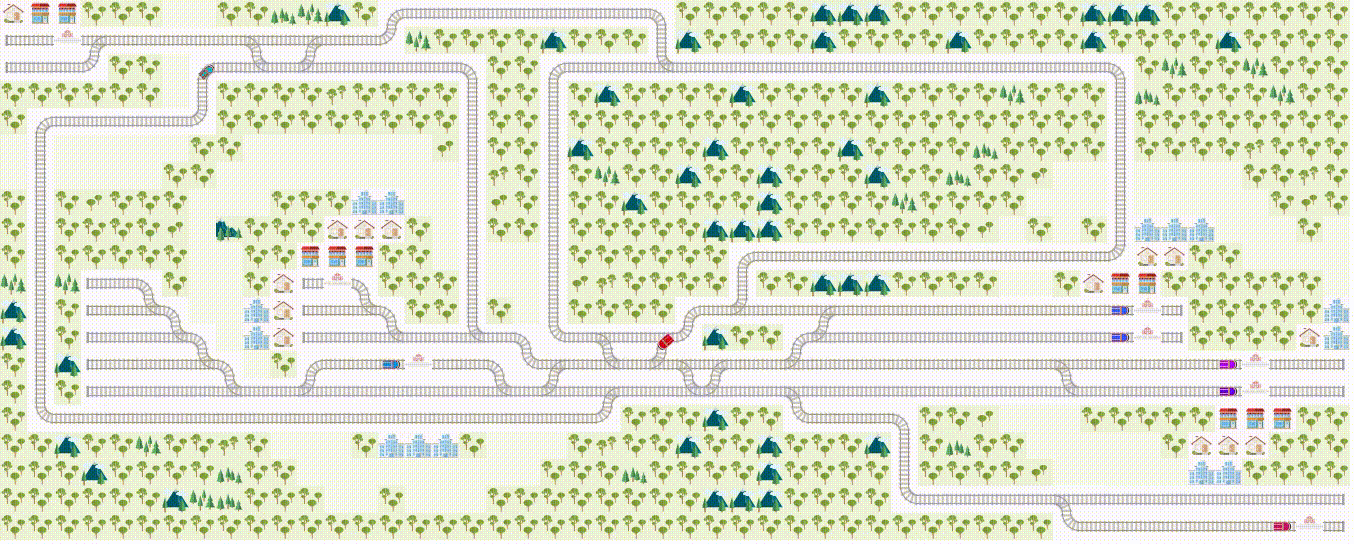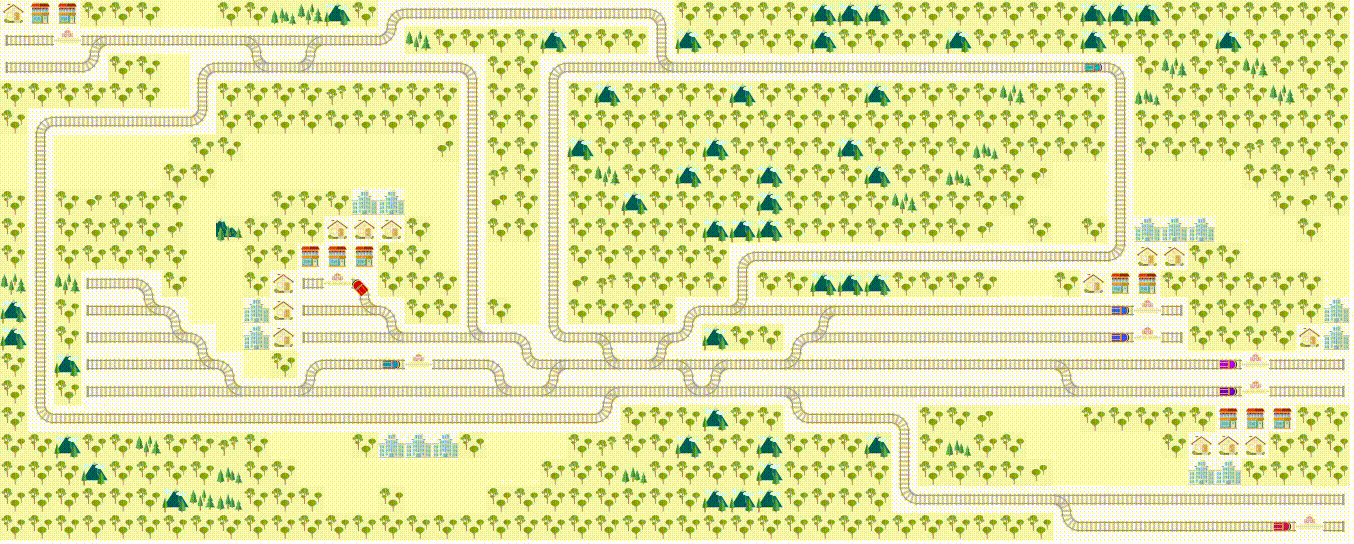
Upcoming RL workshop at AMLD at AIcrowd!
With all the positive feedback and support we received for our last RL workshop, AIcrowd will be hosting a new exciting RL event at the beginning of next year! Mark your calendars for AIcrowds’ interactive Reinforcement Learning workshop at AMLD conference 2021!
Comments
You must login before you can post a comment.
You may also like...
snehananavati
 marcel
marcel
 aryankargwal
aryankargwal