
 Poznań, PL
Poznań, PL
Activity
Challenge Categories
Challenges Entered

Revolutionising Interior Design with AI
Latest submissions
See All| graded | 251760 | ||
| graded | 251750 | ||
| graded | 251584 |

Small Object Detection and Classification
Latest submissions

Understand semantic segmentation and monocular depth estimation from downward-facing drone images
Latest submissions
See All| graded | 216814 | ||
| failed | 216802 | ||
| failed | 216792 |

Identify user photos in the marketplace
Latest submissions
See All| failed | 218195 | ||
| graded | 216523 | ||
| graded | 216520 |

A benchmark for image-based food recognition
Latest submissions
| Participant | Rating |
|---|---|
 siavash
siavash
|
0 |
 mayank_sharma2
mayank_sharma2
|
0 |
| Participant | Rating |
|---|---|
 unnikrishnan.r
unnikrishnan.r
|
261 |
 kbrodt
kbrodt
|
0 |
-
StableDesign Generative Interior Design Challenge 2024View
Generative Interior Design Challenge 2024

Top teams solutions
About 2 years agoAs now official result are released, here is the blog post for 2nd place solution:
🏆 Generative Interior Design Challenge: Top 3 Teams
About 2 years agoI agree that XenonStack has the weakest geometry among top4. This is why I hope that organizers will share leasson learned about their evaluation process.
🏆 Generative Interior Design Challenge: Top 3 Teams
About 2 years agoI understand your standing. This competitions was novel. I have never seen a competitions that try to judge the generated images, marks can be subjective, also seed of model can change a generated image a lot.
I would say that organizers made a good job in competitions organization. Still there were some flaws, like lack of example of scored images (to understand better what does realism and functionality may mean for annotators). Also 3 exemplar images were not enough (that was fixed).
As a team, we found some correllation between quality of generated images and scores (but it was no perfect), especially keeping a right geometry has a lot of impact on score. And they ‘prompt consistency’ was also simple to follow.
I hope that organizers will share publicly some lesson learned from this competition as it could be usefull for the whole GenAI community.
Could you explain Private LB shakeup?
About 2 years agoI’m not sure what happened in Private LB as all top3 teams from Public LB are outside top3 now.
I know that Public LB was evaluated by non-expert and Private LB by an interior design expert. But how come top10 and top11 can be top2 and top3? Does it mean that Public LB was just random?
The second topic is the evaluation criteria in Private LB as they changed a lot compared to Public LB. I would say that in Private LB expert didn’t pay attention to details, whereas annotators in Public LB have seen ~1k images and are even better trained than the expert (in my opinion).
Here are a few examples
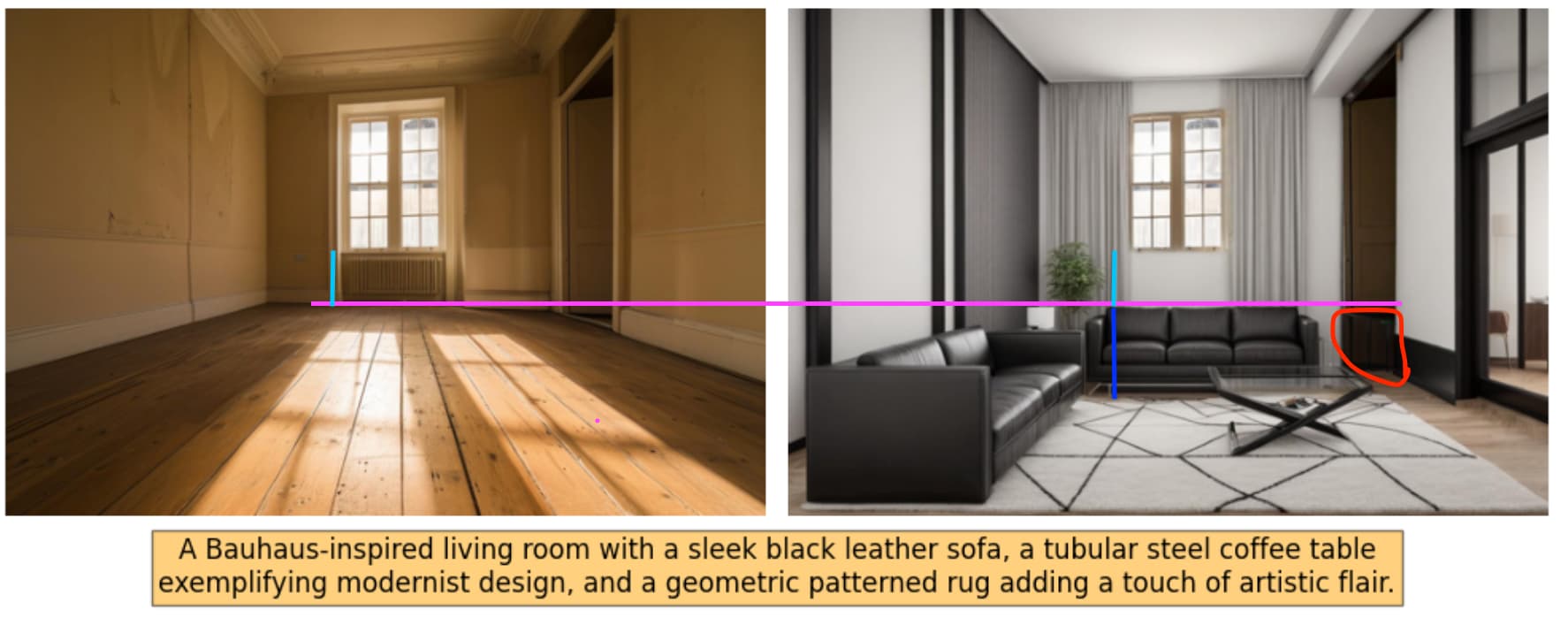
This team has 0.93 geometry. But this image completely changed the height of the floor. According to the rules
cannot be easily altered through basic renovation image should have 0 for geometry.Also some anomalies below the door. Lastly, subjectively, all furniture all small compared to windows/doors, like for kids → for me it means low realism

Here, for example, the wall was moved to the left (check blue lines). Again
cannot be easily altered through basic renovation, 0 score. + Everything is so small, not realistic


Here are also images top3. We have a double chandelier, no bed with a tufted headboard, no mirrored furniture. For me low realism and functionality for both images.

Here again, the floor was moved by ~1m, which should be a score 0. Also some new wall on the right that also require a lot of work to build.

That image is really cool. The only things are the wall was moved on the left side + left windows was transformed into a wardrobe.

Here we have: a window in a window, a new door, second chandelier (it is fine, but realism should go low).
Of course, our generation is not perfect either.
Like:

Double-bed (points for prompt, but low realism and functionality)
But, during the course of the competition, we tried to eliminate geometric issues (and for better geometry, we got better Public LB) but it was not worth it.
I know that is only a cherry-pick.
But I would like to ask the organizers to explain this huge shape-up, why evaluation criteria changed so much (again, top10 and top11 in Public are top2 and top3 in Private), and why wall/floor movement, adding a door does not lead to 0 scores (maybe it is, but if I have seen sth in these 3 images, I belive the error can be repeated in other, this was the case for our team). Maybe it would be better if both non-experts and experts were judging the generations.
Submission Timeout
About 2 years ago@aicrowd_team Could you explain to me why this submission failed during the predictions?
I see there is only this error, but not sure what is wrong. I understand that my code didn’t produce the output within 60 minutes but I don’t get the reason why (as everything works on my Mac). I plan to check everything using Docker
Error Timeout while creating agent, start time needs to be within 60 mins
raw_response, status, message = self.process_request(
File "/home/aicrowd/.conda/lib/python3.9/site-packages/aicrowd_gym/clients/base_oracle_client.py", line 99, in process_request
"data": self.route_agent_request(
File "/home/aicrowd/.conda/lib/python3.9/site-packages/aicrowd_gym/clients/base_oracle_client.py", line 129, in route_agent_request
return self.execute(target_attribute, *args, **kwargs)
File "/home/aicrowd/.conda/lib/python3.9/site-packages/aicrowd_gym/clients/base_oracle_client.py", line 142, in execute
return method(*args, **kwargs)
File "/home/aicrowd/aicrowd_wrapper.py", line 30, in raise_aicrowd_error
raise NameError(msg)
NameError: Timeout while creating agent, start time needs to be within 60 mins
Question about test images and prompt
About 2 years agoFollow-up questions.
Do all prompts in the test-set focus on living room/bedroom creation? Or also bathrooms, and kitchens?
Visual Product Recognition Challenge 2023
Our solution for Visual Product Recognition Challenge
About 3 years agoCould you explain the re-ranking part of the code? I mean code starting here: my_submission/mcs_baseline_ranker.py · main · strekalov / 1st place solution Visual Product Recognition Challenge 2023 · GitLab
2nd place solution for the challange
About 3 years agoI decided to write a blog-post: 2nd place solution for AI-Crowd Visual Product Recognition Challenge 2023 | by Bartosz Ludwiczuk | Apr, 2023 | Medium
If you have any questions, just let me know!
My solution for the challenge
About 3 years agoForgot to mentioned, I was using PyTorch 2.0 and it was game changer for both, training and inference time.
My solution for the challenge
About 3 years agoAbout ViT-H, based on your code you were using ViT-H while training, so I understand that you have used it in inference, am I right?
About using ViT-H for inference, it was not a big deal for me, it was just working without any issue, The code for Vit-H looks like that (I used jit trace as it is faster than script TorchScript: Tracing vs. Scripting - Yuxin's Blog)
self.model_scripted = torch.jit.load(model_path).eval().to(device=device_type)
gallery_dataset = SubmissionDataset(
root=self.dataset_path, annotation_file=self.gallery_csv_path,
transforms=get_val_aug_gallery(self.input_size)
)
query_dataset = SubmissionDataset(
root=self.dataset_path, annotation_file=self.queries_csv_path,
transforms=get_val_aug_query(self.input_size), with_bbox=True
)
datasets = ConcatDataset([gallery_dataset, query_dataset])
combine_loader = torch.utils.data.DataLoader(
datasets, batch_size=self.batch_size,
shuffle=False, pin_memory=True, num_workers=self.inference_cfg.num_workers
)
logger.info('Calculating embeddings')
embeddings = []
with torch.cuda.amp.autocast():
with torch.no_grad():
for i, images in tqdm(enumerate(combine_loader), total=len(combine_loader)):
images = images.to(self.device)
outputs = self.model_scripted(images).cpu().numpy()
embeddings.append(outputs)
My solution for the challenge
About 3 years agoI would say that your solution is quite similar to what I had at some point during this competition.
- was using the same repo as baseline, mean 4th place from Universal Embeddings
- also Vit-H (not sure if you checked the weights from this repo, but just using it I could get ~0.56 in round-1, without any training)
Also, what about post-processing, did you use any technique like Database-side augmentation?
These post-processing techniques could boost my score in Round 1 from ~0.64 to 0.67.
I’m also gonna describe my solution in blog-post (to describe my whole journey) then we can compare our solutions:)
Fail Running Private Test
About 3 years agoThe same thing from my side: 216520.
Also as I understand, the current scores are still from Round-1 as they are exactly the same. The standing is a little bit different as some runs were rejected because of failure (presumably in the private set).
📥 Guidelines For Using External Dataset
About 3 years agoI’m using the following dataset:
Pretrained models:
Previous successful submissions failing
About 3 years agoI don’t know the reason of failures but I can advise you to not to include .git file in your Docker image (if you created your own). In my case removing .git file make all pipeline running smooth.
Product Matching: Inference failed
About 3 years ago@dipam Could you check submission: 213161?
The diagram shows that everything worked fine, but the status is failed:
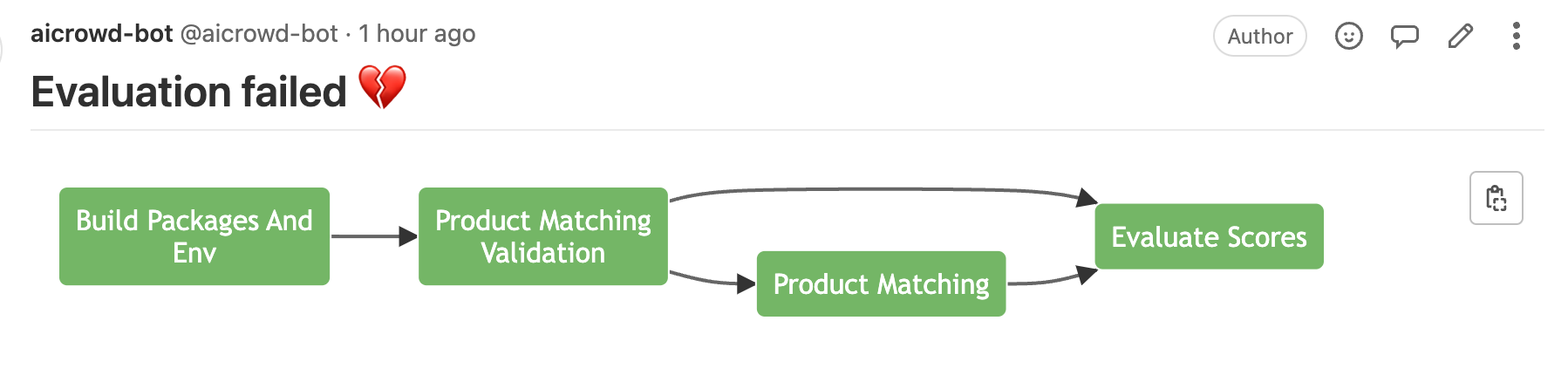
Product Matching: Inference failed
About 3 years ago@dipam
Could you add an error to the following inference errors:
- #211884
- #211754
Product Matching: Inference failed
About 3 years agoHere is the list of submissions with weird errors:
- 211521 (env failed)
- 211522 (env failed)
- 211387 (Product Matching validation time-out, but I don’t see logs for loading the model)
Also, could you also check out what happened here?
- 211640 (I think the error is on my side)
Product Matching: Inference failed
About 3 years agoHi @dipam. Could you send me the errors for error for this submission?
211540
Also, I can mention that in my last 4 failed submissions, 3 were because of aicrowd platform.
- 2x Build-Env failed, when nth was changed in dependences (try in next day succeeded)
- 1x Product MatchingValidation time-out where in logs it not even started
Not sure if AiCrowd has changed sth or if it was just errors coming from Cloud Provider
Second round?
Almost 2 years agoEverything is finalized. There was an award ceremony on the 17th of April.
The top 3 places haven’t changed from the AiCrowd announcement: 🏆 Generative Interior Design Challenge: Top 3 Teams
In fact, there were more than 2 rounds.
4., 4th round → judge the quality of top3 teams again, but now different set of experts