
 Lausanne, CH
Lausanne, CH
Activity
Challenge Categories
Challenges Entered

A benchmark for image-based food recognition
Latest submissions
See All| graded | 177364 | ||
| graded | 177282 | ||
| graded | 177278 |

Machine Learning for detection of early onset of Alzheimers
Latest submissions

The first, open autonomous racing challenge.
Latest submissions

Latest submissions

A benchmark for image-based food recognition
Latest submissions
See All| graded | 124065 | ||
| failed | 124043 | ||
| graded | 124025 |
| Participant | Rating |
|---|
| Participant | Rating |
|---|
-
Gaurav-Eric ADDI Alzheimers Detection ChallengeView
Food Recognition Challenge

Docker Containers for Submission with mmdetection
Over 5 years agoThey are upload to DockerHub, so you can retrieve them with
docker pull skooch/mmdet-aicrowd-latest
Or you can reference them in your Dockerfile :
FROM skooch/mmdet-aicrowd-latestIncorrect Bboxes
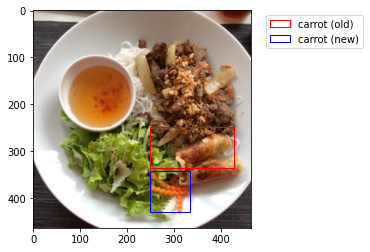
Over 5 years agoWhile the masks seem to be correct, it seems that many of the images in the train dataset have bboxes that do not match the masks. While some of the bboxes are merely slightly off, many are drastically off, as we can see in the examples below.
If you are using the bboxes in training, this may cause problems as the model will be attempting to learn using incorrect bboxes. I wrote the following code to recreate the bboxes based on the masks :
import json
from pycocotools.coco import COCO
def create_new_bboxes(item, coco_ds):
try:
# convert the item to a binary mask
bin_mask = coco_ds.annToMask(item)
# sum the rows and cols
row_sums = bin_mask.sum(axis=1)
col_sums = bin_mask.sum(axis=0)
# find the first non-zero row
for ty, row in enumerate(row_sums):
if row > 0:
break
# find the first non-zero col
for tx, col in enumerate(col_sums):
if col > 0:
break
# find the first non-zero row from the end
for by in range(len(row_sums) - 1, 0, -1):
if row_sums[by] > 0:
break
# find the first non-zero col from the end
for bx in range(len(col_sums) - 1, 0, -1):
if col_sums[bx] > 0:
break
item['bbox'] = [tx, ty, bx-tx, by-ty]
except Exception as e:
print("Error with image", item['image_id'])
print(e)
return item
def rebbox_dataset(annotations):
# create our coco object
coco_ds = COCO(annotations)
# load the data
with open(annotations) as f:
data = json.loads(f.read())
for i, item in enumerate(data['annotations']):
data[i] = create_new_bboxes(item, coco_ds)
return data
In the images below, the red box is the bbox from the annotation and the blue bbox is a box derived from the mask.




Docker Containers for Submission with mmdetection
Over 5 years agoI also have an image for Detectron2 - the latest version - with PyTorch 1.7, CUDA 10.1, torchvision 0.8.1. Note that the starter notebook uses an older version of Detectron and PyTorch which I have not checked for compatibility.
- skooch/detectron2
This image is based on the official Detectron2 Docker image, you would need to copy your code into it and install aicrowd tools like coco, pycocotools, aicrowd_api, and aicrowd-repo2docker.
Docker Containers for Submission with mmdetection
Over 5 years agoWhen I first started working on this challenge I spent a lot more time trying to get the submissions working without errors than I did on training the models. Much of this time was spent trying to debug the building and execution of the Docker containers.
To avoid this problem I have created two Docker images for mmdetection :
- skooch/mmdet-aicrowd - contains PyTorch 1.2, CUDA 10.0, and mmdet v1.0rc1
- skooch/mmdet-aicrowd-latest - contains PyTorch 1.6, CUDA 10.1, and the latest version of mmdet
If you are using mmdetection, you can build your containers from these images and your submissions will run faster (since the images are already built) and hopefully your submissions will fail less.
Images with Incorrect Annotations
Over 5 years agoIn the starter Detectron notebook we have seen that some of the images have incorrect sizes in the annotation file. It turns out that these images also have rotated masks, as we can see in this notebook :
Visualisation of Bad Annotations
While the number of images with this problem is relatively small, we can prevent these errors from being included in the training data by either rotating the masks or removing the images from the training set.
Erroneous annotations
Over 5 years agoImage id 8619 is one of the ones that has it’s width and height transposed in the annotations.json file. I suspect these errors are related.
Detectron2 GPU
About 5 years agoI have an image for Detectron2 - the latest version as of a few months ago - with PyTorch 1.7, CUDA 10.1, torchvision 0.8.1, that I have verified as working for submissions. If I remember correctly you may need to set a flag when installing