
 DE
DE
Activity
Challenge Categories
Challenges Entered


| Participant | Rating |
|---|
| Participant | Rating |
|---|
NeurIPS 2020: Procgen Competition

Selecting seeds during training
Almost 6 years agoMy auto curriculum algorithm just alters the way seeds are sampled to provide much more useful data to the agent and hence improve sample efficiency. Having more seeds than 100 or 200 doesn’t even help in my opinion.
Selecting seeds during training
Almost 6 years agoI guess my assumption is correct since nobody negates it.
It is a pity that Curriculum Learning cannot be done during this challenge.
Selecting seeds during training
Almost 6 years ago@mohanty
I’d like to explicitly set a distinct seed for each worker during training, because I’ve got a concept for sampling seeds.
The implementation would probably look similar to this:
https://docs.ray.io/en/master/rllib-training.html#curriculum-learning
As far as I know, the Procgen environment has to be closed and instantiated again to apply a distinct seed (num_leves = 1, start_level = my_desired_seed), because I cannot enforce a new seed during the reset() call.
So I assume that 200 seeds will be sampled uniformly and it will not be possible to inject my logic to alter the sampling strategy of the 200 seeds.
Selecting seeds during training
Almost 6 years agoHi!
How are you enforcing the usage of 200 training seeds once submitted?
I’m planning on a submission that has some logics to sample certain seeds for each environment.
And as far as Procgen is implemented, I’d have to close and instantiate again the environment to apply the designated seed.
FAQ: Regarding rllib based approach for submissions
Almost 6 years agoIs there any kind of interface that could be used to dynamically tell each environment instance which seed to use? I’ve got some curriculum concepts to sample seeds during training.
From first sight, I think that this is way too cumbersome using RLlib.
Multi-Task Challenge?
Almost 6 years agoAccording to this image, each environment is being trained and evaluated solely.
After all, the agent gets to train on the unknown environments as well, right?
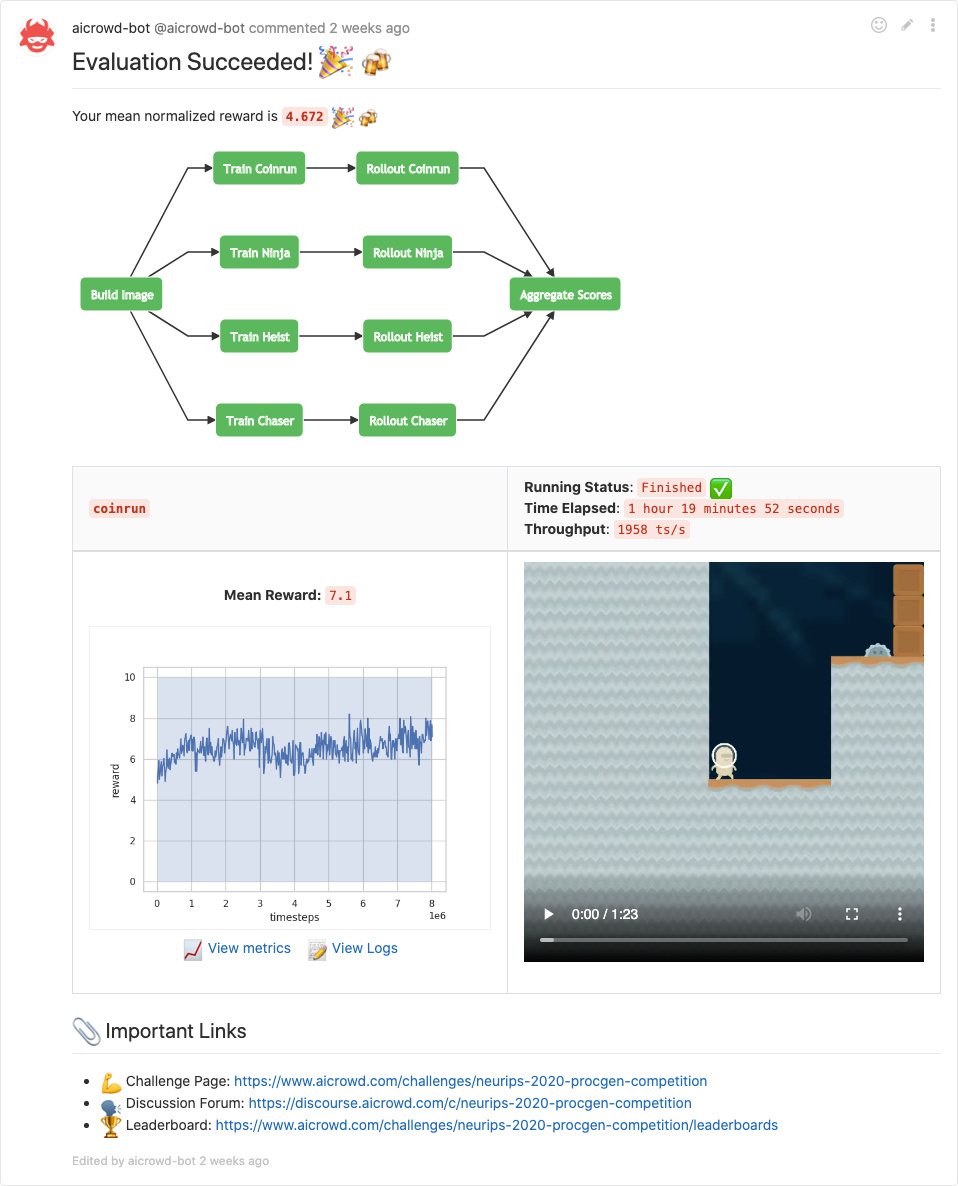
And does this image mean that the training and the evaluation are done on your side?
Multi-Task Challenge?
Almost 6 years agoHi!
I’m wondering whether this competition challenges us with a multi-task setting.
To my understanding, one agent shall train on 16 environments So this agent/model should be able to play each environment and the 4 unseen ones, right?
Unity Obstacle Tower Challenge
Good testing environment that does not need X?
Almost 7 years agoUnfortunately I did not find one yet.
Release of the evaluation seeds?
Almost 7 years ago1001, 1002, 1003, 1004, 1005 are the evaluation seeds.
The environment’s source is finally available.
Submissions are stuck
Almost 7 years agoAre you going to fix the bug of the show post-challenge submission button?
Pressing this button does not change the leaderboard.
Good testing environment that does not need X?
Almost 7 years agoHey,
do you guys know of an environment, which would be suitable for testing DRL features?
Obstacle Tower takes too much time as well as the dependency of using an X server is daunting.
I’m working on two clusters, one in Jülich and one in Dortmund and neither of them has a suitable strategy for making X available. X needs root privileges to be started and that’s basically their major issue.
If X was not an issue, I would build myself a Unity environment.
Does anybody know if Unreal Engine is dependant on X as well?
Release of the evaluation seeds?
Almost 7 years agoHey @arthurj
when could we get an OT build with the evaluation seeds?
I guess we all would love to see what our agents are capable of doing.
Thanks for the great challenge!
Submissions are stuck
Almost 7 years agoMonday as a deadline is kind of a bad choice, because debugging the submission process on a weekend does not sound feasible.
Is the evaluation seed truly random?
Almost 7 years agoDue to the very stochastic nature, I think more trials on the evaluation seeds would mitigate the strongly varying results. So just resubmitting the same agent may yield in much better or much worse performance.
Evaluation perspective config?
Almost 7 years agoI assume that the circumstances of the evaluation will be the same for every participant.
Evaluation perspective config?
Almost 7 years agoThe evaluation config uses the default values such as 3rd person view.
Problems of using rllib for a research competition
Almost 6 years agoI decided to not participate in this competition as well, due to the aforementioned constraints. I’ll continue using Procgen though using my established workflow and code.