
 GB
GB
Activity
Challenge Categories
Challenges Entered

Play in a realistic insurance market, compete for profit!
Latest submissions
See All| graded | 125317 | ||
| graded | 123877 | ||
| graded | 122529 |
| Participant | Rating |
|---|---|
 lolatu2
lolatu2
|
0 |
 simon_coulombe
simon_coulombe
|
0 |
| Participant | Rating |
|---|
Insurance pricing game

Python Solution sharing
About 5 years agoThere are the workbooks and videos shared by the organisers,

The github repository of Simon Coulombe
The Kaggle examples from Floser
https://www.kaggle.com/floser/glm-neural-nets-and-xgboost-for-insurance-pricing
Failing all of that then do as I first did. Calculate a premium = 114 and submit that and build from that position.
There should be enough resources already shared for you to get going.
Weekly Leaderboard
About 5 years agoYes @michael_bordeleau I kept with the same claims model (which I’m now convinced underfits to the data) and reduced my profit load by approximately 5%. My market share went from 0.7% to 14.8% a level I’d be happy with but because my model doesn’t differentiate risk as well as others then I picked up too many claims, especially in the 5k to 10k bucket.
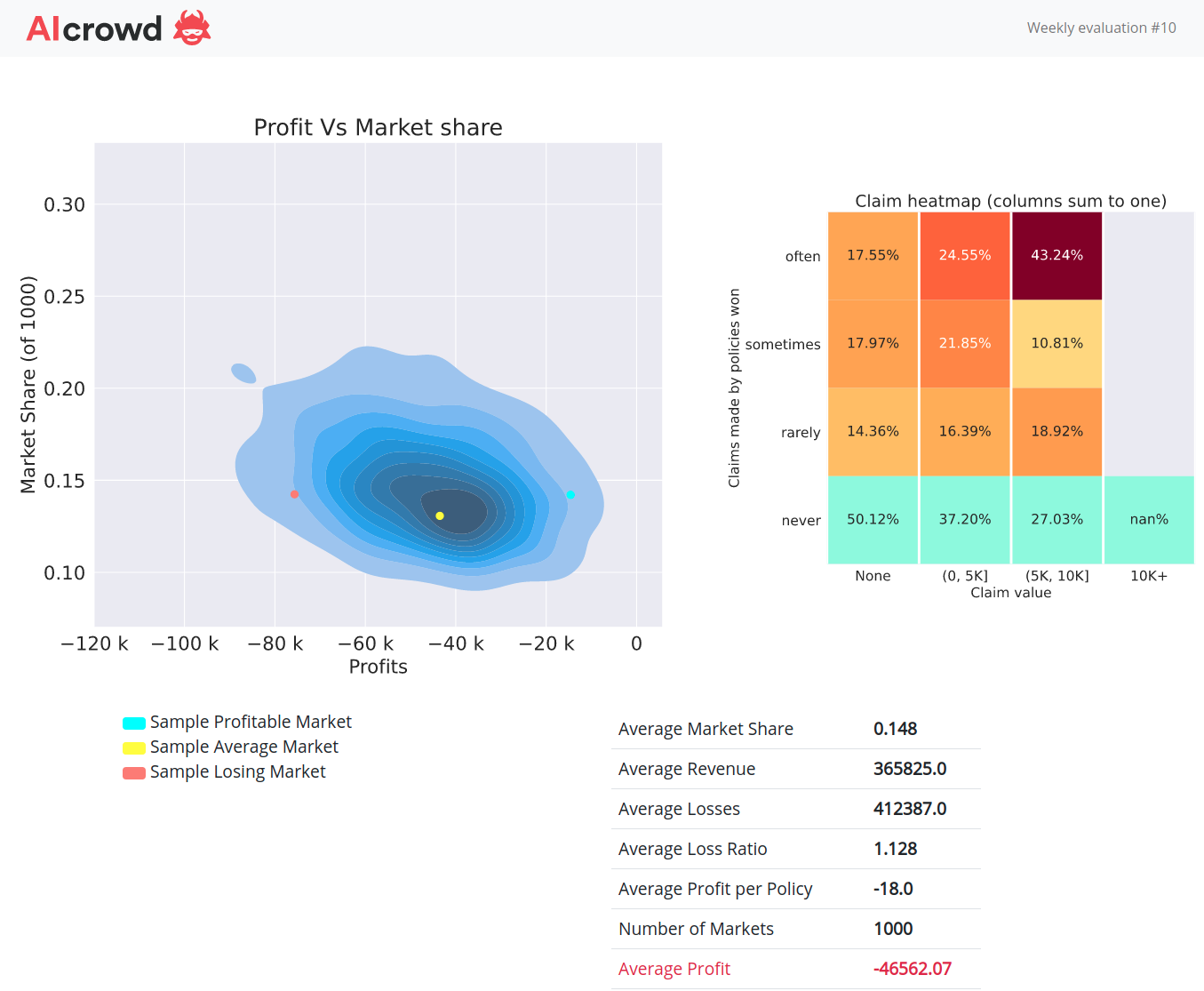
Overall I now think I’ve got a good handle on the right profit margin distribution. Now just have to tweak the underlying claims model.
Interesting to hear your comment on staying with your current model. I certainly won’t be going with my current one. The final week is very different to all that have gone before and that gives rise to the ability to use a new feature that is likely to be very predictive but which up until now no-one has been able to exploit…
Weekly Leaderboard
About 5 years agoSame for me, made a submission got weekly feedback but the submission is not appearing on the leaderboard.
Was week 9 a lucky no large claims week?
About 5 years agoIf I assume that’s your feedback from week 9 submission then I’d conclude that it’s not ideal.
In many ways it’s similar to my week 8 submission when I had a similar looking chart, a similar high market share and a low leaderboard position. The difference is my week 8 RMSE model was 500.1 ish and your week 9 is 499.46 ish.
Now you’d hope that a model with a much lower RMSE should be better at differentiating risk. If that was the case though you’d expect to write a smaller market share of the the policies with higher actual claims. Your chart though doesn’t show such behaviour. That may be because your good performance on the public RMSE leaderboard is not generalising to the unseen policies in the profit leaderboard. This could be a result of placing too much emphasis on RMSE leaderboard feedback and not enough on good local cross validation results. It can lead to unwittingly overfitting to the RMSE leaderboard at the expense of a good fit to unseen data.
Now I think I have a similar issue, ie a poor fitting model as my week 8 and week 9 charts are less that ideal… (I’d rather have a chart like @davidlkl but with greater market share). But the cause of my issue is that in seeking not to overfit too much I haven’t fit well enough relative to others.
Another point to investigate is your market share. A 30% market share, suggests your profit margin is set lower than competitors. In a pool of 10 people a 10% market share would be a a reasonable target to go for.
The only difference between my week 8 and week 9 submission was that I increased my rates by a fixed single digit percentage. I’ve learnt that I perhaps increased rates too much as my market share has fallen further than I’d like.
So for my final submission I’ll be refining my model and making a minor tweak to my profit margin. (And no doubt subsequently regretting doing so as I see my profit leaderboard position plummet!)
Was week 9 a lucky no large claims week?
About 5 years agoOK so that’s helpful to know nan% is a possible output. So as in week 9 I got 100% in the “never x 10k+” claims heatmap cell it means there were some policies in the market that had claims in the 10k+ range.
I haven’t really changed my claim model for the last 5 weeks or so. All I’ve been doing is tweaking pricing strategy, gradually edging rates up. When there have been large 50k capped claims in the market historically I’ve been rather good at writing them and therefore ended up with a low leaderboard position. When, I suspect, there haven’t been many large losses (week 5 and 9 ?) I end up in a reasonable leaderboard position (1st and 3rd).
I’d be really interested to know if anyone thinks there were any 50k capped losses in this round. Sometimes you can tell because your profit exhibit is centered around -50k or -100k and the claims heatmap exhibit will say 100% in the “often x 10k+” cell.
Like my week 8 chart…
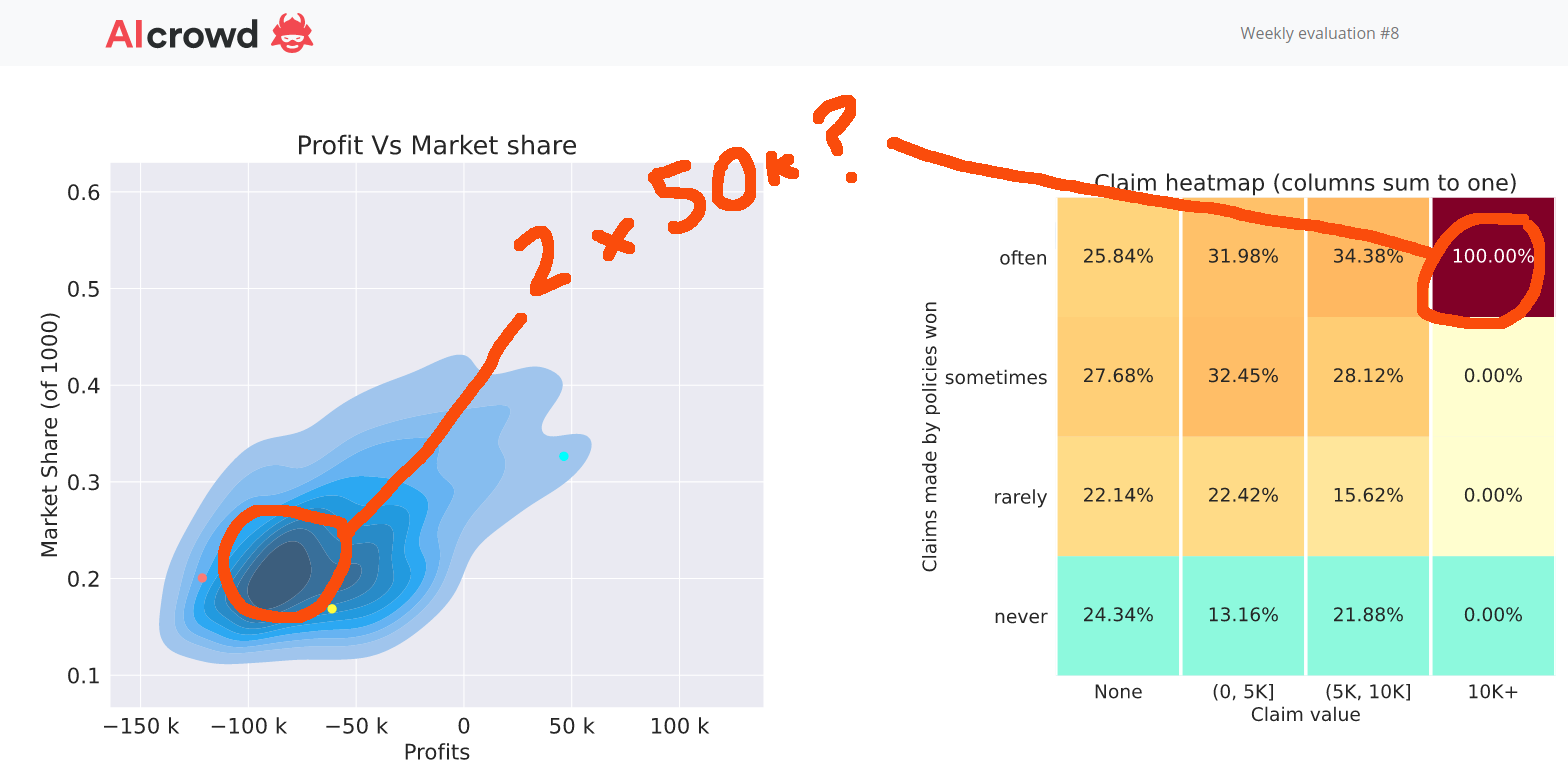
If there were 50K claims and I avoided them then maybe I’ve found the right level of premium loading to claims. More likely though that my margin is too high now, given my small market share, and I’ve got lucky on the policies I did write.
Was week 9 a lucky no large claims week?
About 5 years agoSharing some of my leaderboard feedback hoping to get some insight on large claims in week 9…
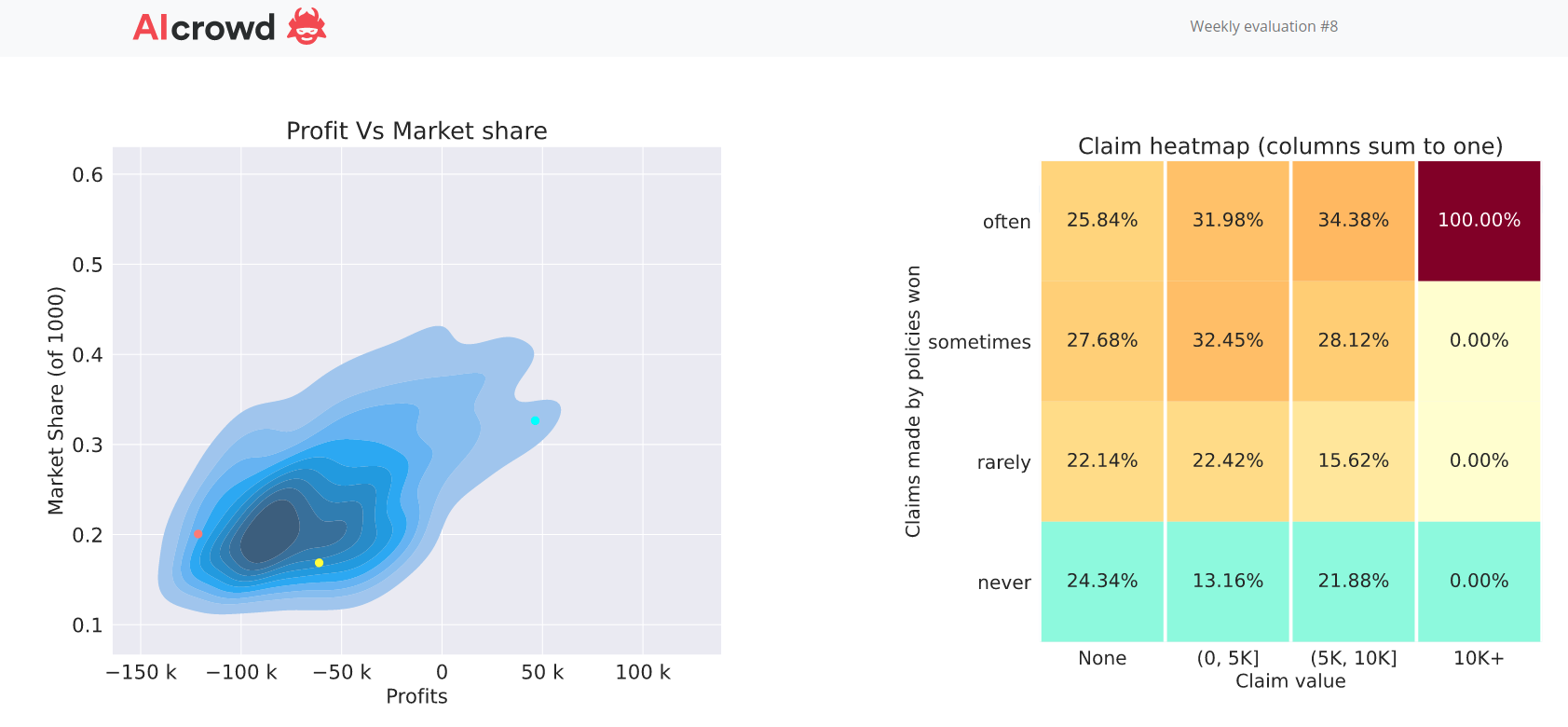
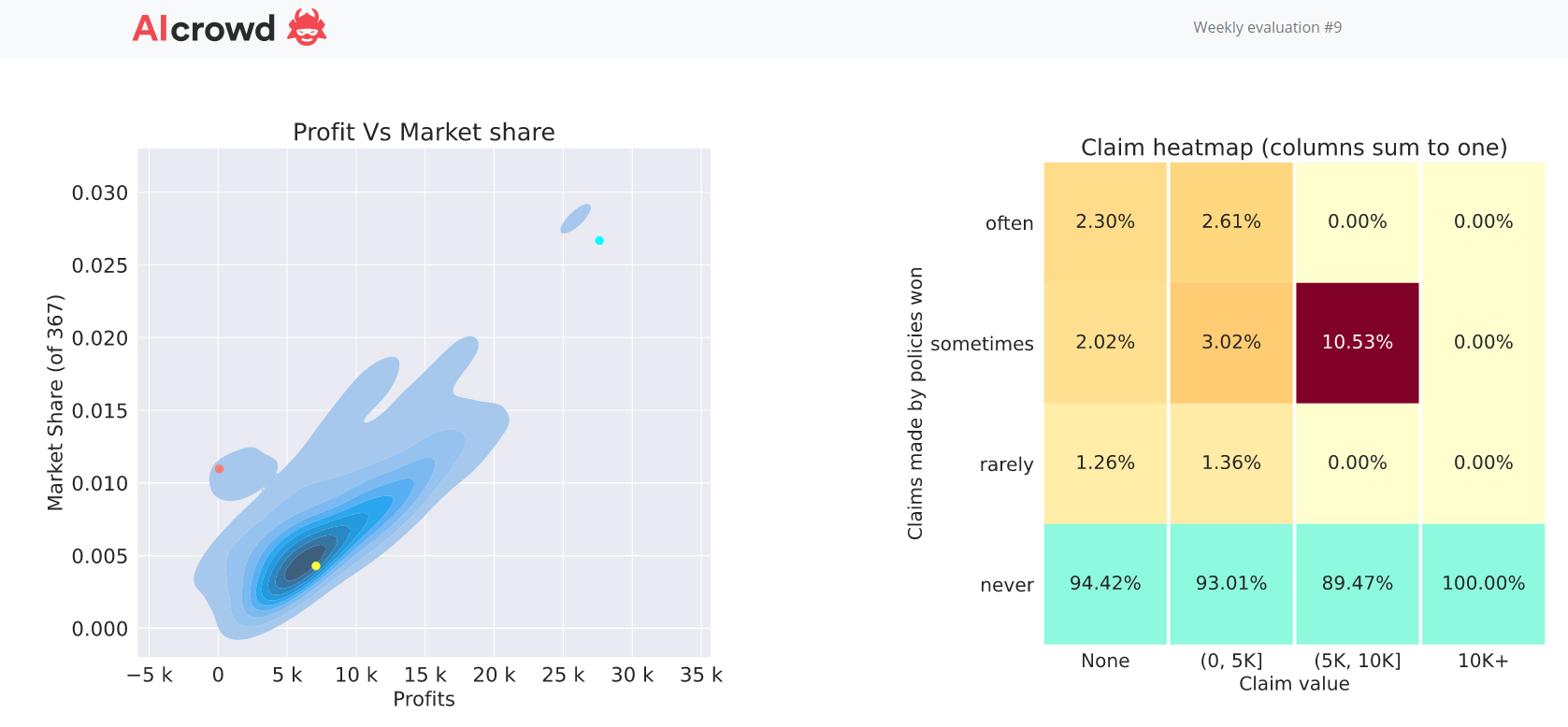
So I didn’t change my underlying claim model between week 8 and week 9, I just increased my rates by a uniform single digit number and I go from 90 to 3 on the profit leaderboard.
If I look at the overall leaderboard I see that many more of us actually made a profit this time. Makes me wonder whether this was another lucky no large claims week? However because I didn’t write any this week  I can’t tell if I avoided them by my skill at rating or by the luck of there being none to avoid.
I can’t tell if I avoided them by my skill at rating or by the luck of there being none to avoid.
Week 8
Week 9
R Starterpack (499.65 on RMSE leaderboard - 20th position) {recipes} + {tweedie xgboost}
About 5 years agoA few years ago a member of my team, who is an actuary and Kaggle master, used to delight in tormenting the rest of us when his models out-performed ours on leaderboards.
He would always insist his out-performance was due to his process of selecting lucky seeds.
We all knew full well there’s no such thing, that generalises to the private leaderboard, but many a time I caught myself trying a few different seeds to see if I can get lucky and beat his model.
There is of course nothing wrong in running a few models with different seeds and taking the average result. That’s a recognised technique called bagging which will often improve a model at the cost of implementation complexity.
Values in new heatmap changed between sunday and today?
About 5 years agoGood spot… but I have to say I don’t like what the new one is telling me!
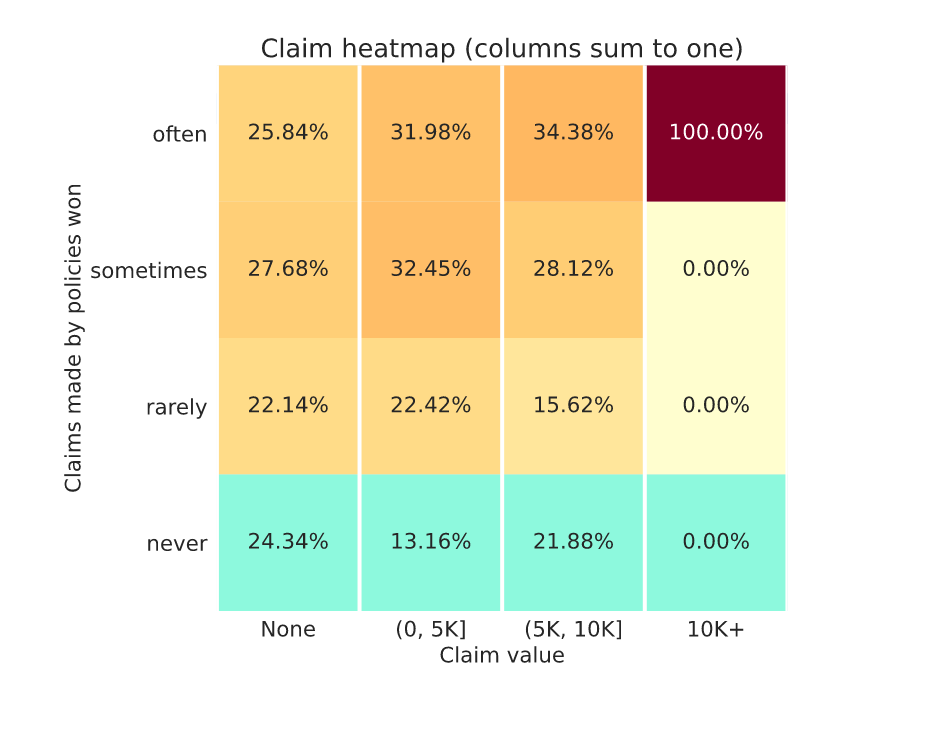
A potential silver lining is that… maybe in my model I have found a way of identifying all the policies with large claims… now all I need to do is stop writing them! 
Weekly Feedback // Evaluation clarification?
Over 5 years agoGood luck Michael with the strategy for gaining market share to improve profit.
I had the winning model for week 5. I kept it unchanged for week 6 and we can all see what happened I ended up in 63rd position. Given my current strategy isn’t giving consistent results I’m going to change it so feel it’s OK to share my feedback from weeks 5 and 6.
In week 5 I wrote a market share of 13%, avoided any large claims (maybe there weren’t any) and managed the following.
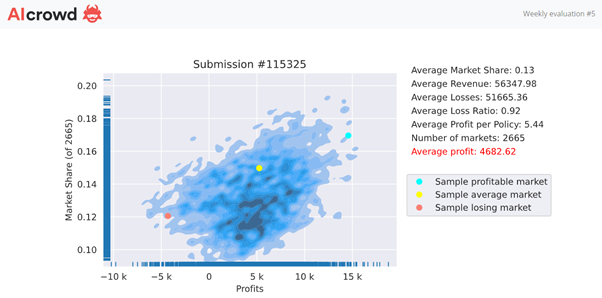
Looking good I thought, so let’s leave it unchanged for week 6… Ouch…
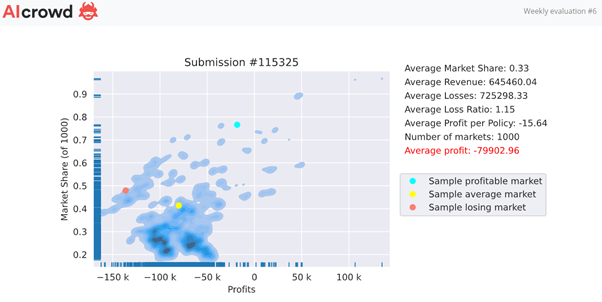
So there are few things of interest.
First, I gained market share. That shouldn’t surprise us… as a market on average we’re doing a good job of losing money, so I could believe that market rates are rising as the weeks go by.
Second, gaining market share means an increased likelihood of picking up large claims. It looks like there were 3 large claims (given claims are now capped to 50k) in the week 6 market and lucky me managed to pick them up more often than not.
If you believe large claims are predictable and you’ve set your rates accordingly then they shouldn’t worry you.
But if you think they are largely random then we are all playing a game of chance. In that case I suspect the lucky winner will be someone who sets their rates at an uncompetitive level, writes a small but profitable market share and avoids the large claims to take home the prize.
Time will soon tell, but in the meantime I’m going to go back to the data once more to see what I can make of the large claims. An then I had a cunning plan to prevent me from repeatedly picking up the large claims in the leaderboard calc which @alfarzan has just scuppered by declaring that the leaderboard is now calculated deterministically rather than by simulation as was the case!
Ideas on increasing engagement rate
Over 5 years agoI think my regulator would object to me sharing price sensitive information… I’ll let you know next year when the reserving actuaries publish the results
Ideas on increasing engagement rate
Over 5 years agoI think weekly profit leaderboard revision is enough. There’s a limit in what can be done with the data available and not everyone will have the time to revise their models even weekly.
One tip I’d share is to encourage people to avoid getting trapped in what’s known in Kaggle as a public leaderboard hill-climb. It can result in overfit models which fail to generalise to the unseen data used to determine final rankings.
To illustrate, my week 5 winning profit leaderboard submission is built from a model that scores 500.3 on the RMSE leaderboard ie about position 110.!
There are many sound reasons why we should be ignoring the RMSE leaderboard and putting our trust in a robust local cross-validation approach. Yet I know from bitter Kaggle experience that it’s all too easy to forget this and get carried away by the thrill of chasing leaderboard positions.
Ideas on increasing engagement rate
Over 5 years agoIn preface to my feedback and suggestions below I must first say
- I believe the principle of the competition is great and engaging
- you’ve been really proactive in engaging with competitors and fixing issues as they arise
However I imagine that many of those that have dropped away have done so because their first encounter was difficult and ended in a failed first, second or third submission. At which point they may have quiet reasonably decided to give up.
I’m an experienced Kaggler and the leader of a Data Science team that developed and runs it’s own in-house data science competition platform; so I do appreciate how difficult it is to get this right. The profit leaderboard aspect of this competition, which adds to the fun and engagement, necessitates some complexity in the submission process and behind the scenes will introduce complexity in IT infrastrutre and scoring process.
Unfortunately for competitors they experience that complexity before they get the reward of leaderboard feedback. You can’t remove all of that but you can smooth the way a bit.
Hears my 5 suggestions…
- continue to make your platform more stable and responsive
- continue to make the website cleaner and easier to navigate
- continue to improve the submission process
- if large claims are causing a leaderboard lottery then implement a fix quickly (so people at the top of the leaderboard don’t give up because they know skill may not help them win)
- introduce an element of knowledge share (so people further down the leaderboard aren’t demotivated and drop out)
There will be a limit to what you can do in the time available and I recognise you’ve been working on a number of these aspects already.
The competition and platform now is much better than it was when I was the first person to struggle to make a submission, for which you should be congratulated!
So my final recommendation would be to reach out to people that may have joined early and been put off to let them know you listened to user feedback and made improvements… maybe they’d be encouraged to try again?
Review of week 4
Over 5 years agoConfirm I too saw a small group of exposure with a 150k+ average loss that went with it. I agree that a single large claim in the market would explain things… including the significant shift in positions some high ranking week 3 people saw.
Shame no-one is able to offer any Excess-of-Loss cover. A single large claim like this in the final round could make the final outcome a bit of a lottery!
Inference failed errors
Over 5 years agoTurned out I then hit another error which may worth @alfarzan investigating and other R zip file submission people that have recently upgraded to xgboost 1.3 and are getting submission errors also trying.
I upgraded my local version of xgboost to 1.3 which for R users was released on CRAN in the last week. Anyhow after the upgrade I’ve not been successful in making submissions from locally trained zip file, even though they pass all the local tests as per the zip instructions (and I’ve been making successful zip based submissions in previous weeks with xgboost 1.2.)
Anyhow after I downgraded my local version of xgboost back to 1.2, retrained, re-ran tests which again passed and then reloaded my submission then worked.
Could it be that AICrowd is loading xgboost 1.2 for R users and the models trained with the new 1.3 version have incompatibilities causing submission errors? In which case guess I need to specify my version of xgboost in install packages.
Any tips for successfully submitting an h2o model?
Over 5 years agoYes, it’s hardcoded in the R zip file routine load model which is part of model.R unless you’ve already overidden?
load_model <- function(){
# Load a saved trained model from the file `trained_model.RData`.
# This is called by the server to evaluate your submission on hidden data.
# Only modify this *if* you modified save_model.
load('trained_model.RData')
return(model)
}Inference failed errors
Over 5 years agoNow submissions are working (thanks admins!!) I see I’m not alone in getting inference failed error messages.
In my case it’s because I’ve got inconsistencies between the feature names of my locally trained model and the features names I’ve put in the prepare_data routine of the zip file submission.
Sharing in case it helps other’s get their submission fixed before the extended deadline.
Servers look like they are struggling to process submissions
Over 5 years agoLooks like the servers are struggling to keep up with submissions?
I see a large number of submissions waiting for scores… seems to have been like this since 17:45.
I really should learn not to leave my modelling to a Saturday afternoon. Look’s like this will be the third week in a row that I fail to successfully get my Saturday profit leaderboard submission made before the cutoff!
RMSE evaluation error - "pod deleted during operation"
Over 5 years agoI had a pod timed out error last week. It’s an error message that reminds me of scaling issues with kubernetes clusters, ie issues with the tech behind the scenes of the competition site.
For me the issues appeared to resolve themselves … or more likely went away when the admins did something behind the scenes.
Seeking clarification on model selection
Over 5 years agoThanks @alfarzan that’s enough for me to work on.
To summarise; the competitive profit leaderboard will use the predict_premium function from the last valid upload prior to the weekly Saturday 10pm cutoff.
So I must remember to keep a submission free and make sure I upload in plenty of time for the 10pm cutoff.
Ye olde library
About 5 years agoNot a paper as such but a pricing competition I’ll always remember was the Porto Seguro competition on Kaggle. It was special in that it was the first time I recall seeing xgboost not be the major part of the winning solution. Instead the winner Michael Jahrer used denoising auto encoders (a neural network approach).
Michael won the competition by a wide margin and how he won became a big discussion topic among the Kaggle community, many people trying to replicate his approach.
While we’ve not seen his winning approach port to other competitions with similar success it does, for me, show that when data allows neural network based approaches will outperform the current ubiquitous GBM type approaches.