
Location
 GB
GB
Badges
Activity
Challenge Categories
Challenges Entered

Play in a realistic insurance market, compete for profit!
Latest submissions
See All| graded | 126283 | ||
| graded | 125499 | ||
| graded | 125453 |
| Participant | Rating |
|---|
| Participant | Rating |
|---|
Insurance pricing game

Margins & Price Sensitivity
About 5 years agoSweet solution!
I’ll need to dig out exactly what I did, but I think I came up with an elasticity at 0 of around 20-25 in a vacuum. (so this gives me an idea of the underlying elasticity that exists from the nature of the comp with 10 equivalent competitors, but is probably inferior to your direct market probing) I think I generated a market of 10 competitors using the same lgb model built with 10 different seeds, and then playing around with the load/discount applied to individual competitors etc.
It's (almost) over! sharing approaches
About 5 years agoExactly, many people will have already saved this information in their model (through an extra lookup table), so it makes no difference to them, only to those of us who were expecting the information to process those features “on the fly”.
It's (almost) over! sharing approaches
About 5 years agoYes, I was expecting the same format.
I see what lolatu2 is trying to say, but I don’t buy the arguement that inclduding year1-4 rows is advantageous to michael, myself or others in our position - even if there is only year 5 data, prior year information can still be passed into your model, you just chose not to. I could have created a dataframe which contained all prior year features as part of my “model”, I just chose not to handle all prior year features this way because that would have meant refactoring my code (and it hadn’t even occured to me that this might be necessary, since the competition so far always gave access to prior years for all leaderboards).
It's (almost) over! sharing approaches
About 5 years agoI’m actually a bit miffed tbh, I get that it’s an oversight on our part given the ambiguous wording, but I’ve got a few “NCD history” features embedded in my pre-processing - why would we spend 10 weeks with one data structure (requiring the pre-processing code to calculate these features on the fly), and then have to refactor this for the final submission …
Luckily I’ve got a “claim history” data frame as part of my final “model” which was added last minute and gives some sizeable loadings (over and above my ncd change history feats), so I’ll have some mitigation from that.
It's (almost) over! sharing approaches
About 5 years agoHmm, bugger! I assumed we’d get access to the previous 4 years, akin to the RMSE leaderboard.
Some final thoughts and feedback
About 5 years agoIndeed, I figured there’s a few attributes you could possibly join ext data into if you found it, but I also gave up after an hour or so searching for it.
You are probably wondering how much profit loading to select?
About 5 years agoWell I think this may now be a self-fulfilling prophecy to some extent if people look to your analysis as a guide and everyone just goes with 35%, we shall see 
I’m not feeling as generous as you, so I’m not sharing the details for now, but I’ve been exploring something somewhat similar and get a much lower range (not necessarily correctly).
I’ll throw this in - how bad is your worst model? … is it fair to expect this to make a profit?
Weekly Leaderboard
About 5 years agoGreat idea (although I must say, I hope there’s not too many issues with this week’s LB given my new model got 6th haha)
How are you doing? (Part 2)
About 5 years agoVery interesting!
Nothing immediately comes to mind regarding the Gini volatility, but it’s interesting that it has the best correlation with profit rank.
The stability of the MAE results are interesting too. It’s not worth drilling into … but if you want some ideas about what to try, I’d suggest rebasing your predictions on the training samples (i.e. models always break even on train), this won’t affect Gini, but might shake up the Mae (and maybe rmse) ranks a bit.
Tensorflow models through a colab submission
About 5 years agoI’ve been exclusively training and submitted via google colab notebooks and encounter some road bumps when trying to get tensorflow models submitted. I’m sure this isn’t best practice (please feel free to critique - I’d like to learn better ways!), but thought I’d at least share the outline of how I managed to succeed (there’s been a few related posts already, but I couldn’t completely piece everything together from those).
Problems:
- tensorflow 2.4 isn’t supported in the submission environment
- all “model” components need to be packaged into a single file (zip, pickle, other) - this was slightly painful as I had previously dumped all models/pipelines into dicts and pickled them, but tensorflow models won’t save this way
My solution to tensorflow versioning:
- add the following to your ADDITIONAL_PACKAGES config section:
‘tensorflow==2.3.0’,
‘tensorflow_addons==0.12.1’, # I wasn’t explicit on the install, but checked what version loaded
‘h5py==2.10.0’ # I wasn’t explicit on the install, but checked what version loaded
- pip install the specific version of tensorflow you want (note, you’ll need to restart the runtime afterwards) - I’ve included the bottom four lines below to show you where it goes relative to other code
!pip install tensorflow==2.3
!pip install tensorflow_addons
import importlib
import global_imports
importlib.reload(global_imports)
from global_imports import * # do not change this
My solution to model packaging:
- keep pre-processing in an explicit sklearn pipeline (or dict of multiple pipelines); save tf models to their own separate dict
- then I zip everything during the save / unzip and put back into dicts during the load
I’ve attached my save an load functions (screenshots only sorry - pasting code in here lost all the nesting)

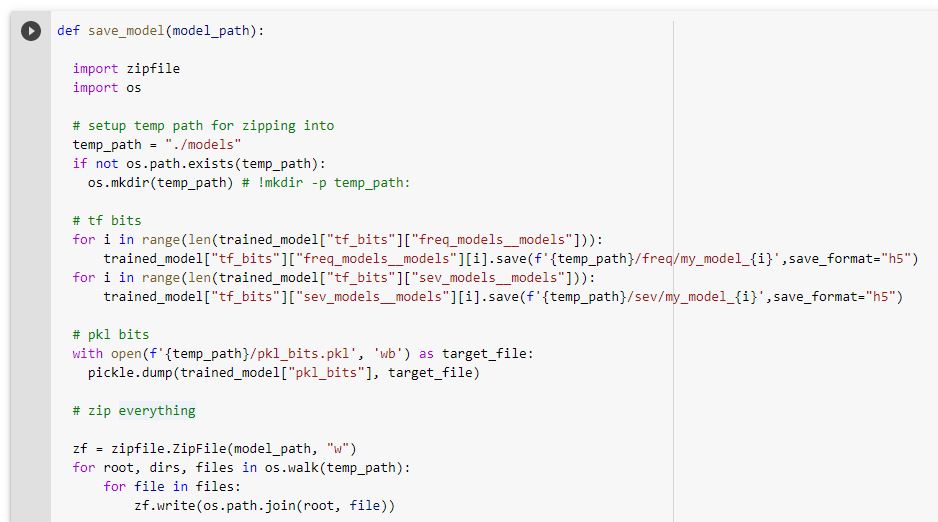
Tom
Error on TensorFlow
About 5 years agoThanks, that forced me to pick between the latest 1.x version or 2.4. However, I’ve got a working submission using pip install. I’m sure I’ve not used remotely best practice, but I’ll write a post on what I’ve done so there’s a framework people can copy (and critique).
Error on TensorFlow
About 5 years agoThanks, that’s got me past a slight inaccuracy with folder paths, but I think I’m now hitting a genuine issue with loading back the tensorflow models. Could you please give me your views on the issues with # 122718? I’ve tested loading back the models (unzipping to a different folder than the one used to zip stuff up) and everything loads and functions as expected in collab.
Edit: I can see that “print(tf.__ version__)” yields 2.4.1 in my collab notebook so that could be the issue? (although I am specifying ‘tensorflow==2.3’ in the config, so not sure how to correct this)
Error on TensorFlow
About 5 years agoHi alfarzan,
Could you please look at submission #122698? I’m getting the similar errors … although I think the issue lies with how I’ve attempted to zip and unzip my model components.
Many thanks,
Tom
ERROR: No matching distribution found for os
About 5 years agoHello,
Could someone please look into the error I’m getting on submission #122644? Everything runs OK in collab, but it looks like I’m unable to use the os package as part of the submission (?).
Thanks,
Tom
How are you doing? (Part 2)
About 5 years agoExcellent post! I’d suggest gini coefficient as an alternative measure - I’ve put a reasonable amount of weight on it personally, and know that it’s commonly used across the insurance industry.

Missing weekly feedback mail
About 5 years agoI can’t see any feedback on my submission for week 8 when I click view (submission id # 119239) - any thoughts on how I can get hold of the information? - I can’t see an “evaluation status” tab.
Thanks,
Tom
You are probably wondering how much profit loading to select?
About 5 years agoAs I didn’t see too much activity on the thread I pretty much ignored the thinking that everyone might jump on 30%+ bandwagon in the end.
My week 10 results had me at 9.4% market share, and I assumed that there wouldn’t be too much market movement between there and the final leaderboard. I ended up going with a final profit strucuture of (X+5)*1.135, which (by some dodgy maths) I thought would land me in a similar position to week 10 (where I had a lower additive and higher multiplicative component - I can’t download the files at the moment, but I think I had an additive of 0.7 and multiplicative load of 23%, plus some other funny business). I placed 6th in week 10, and while I did submit a significantly better model than week 9, I get the impression that there weren’t any 10k+ claims, and that this did me a big favour (I put minimal effort into investigating/protecting against large losses).
I’ve not looked into the error by predicted premium (although I note some convos have started on this on another thread), but under the (naive) assumption that my models are “good” across the spectrum, it makes sense to push for a greater %load on lower premium business (hence the additive) - this was backed up by some simulations of 10 equivalent competitors, 9 with a flat profit load and 1 with the form somewhat like the one I described above (and indeed the load of 5 selected via experimentation).
I don’t think I’ll end up placing highly unfortunately - a combination of me not realising the training data is likely not being provided in the predictions file on the final leaderboard (which means my NCD history features are probably reduced to being a constant NA), possibly being a few % too cheap on average, and not looking to protect enough from large losses will have all cost me … I suspect.