
Location
 CN
CN
Badges
Activity
Challenge Categories
Challenges Entered

What data should you label to get the most value for your money?
Latest submissions

| Participant | Rating |
|---|---|
 wxl121228
wxl121228
|
0 |
 Cocof6d9
Cocof6d9
|
0 |
| Participant | Rating |
|---|---|
|
Cocof6d9
|
0 |
|
wxl121228
|
0 |
-
Zhichun_Road Data Purchasing Challenge 2022View
-
ZhichunRoad ESCI Challenge for Improving Product SearchView
ESCI Challenge for Improving Product Search

【Solution ZhichunRoad】 5th@task1, 7th@task2 and 8th@task3
Over 3 years agoFirst of all, many thanks to the organizers for their hard work(the AICrowd platform& the Shopping Queries Dataset[1]).
And I learned a lot from the selfless sharing of the contestants in the discussion board.
Below is my solution:
+-----------+---------------------------+-------------------+-----------+
| SubTask | Methods | Metric | Ranking |
+-----------+---------------------------+-------------------+-----------+
| task1 | ensemble 6 large models | ndcg=0.9025 | 5th |
+-----------+---------------------------+-------------------+-----------+
| task2 | only 1 large model | micro f1=0.8194 | 7th |
+-----------+---------------------------+-------------------+-----------+
| task3 | only 1 large model | micro f1=0.8686 | 8th |
+-----------+---------------------------+-------------------+-----------+
It seems to me that this competition mainly contains two challenges:
Q1.How to improve the search quality of those unseen queries?
A1: we need more general encoded representations.
Q2.There is very rich text information on the product side, how to fully characterize it ?
A2: As the bert-like model’s “max_lenth paramter” increases, the training time increases more rapidly.
We need an extra semantic unit to cover all the text infomation.
A1 Solution:
Inspired by some multi-task pre-training work[2]
In pre-training stage, we adopt mlm task, classification task and contrastive learning task to achieve considerably performance.

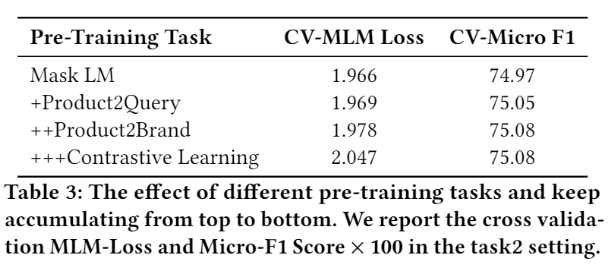
A2 Solution
Inspired by some related work[3,4]
In fine-tuning stage, we use confident learning, exponential moving average method (EMA), adversarial training (FGM) and regularized dropout strategy (R-Drop) to improve the model’s generalization and robustness.
Moreover, we use a multi-granular semantic unit to discover the queries and products textual metadata for enhancing the representation of the model.

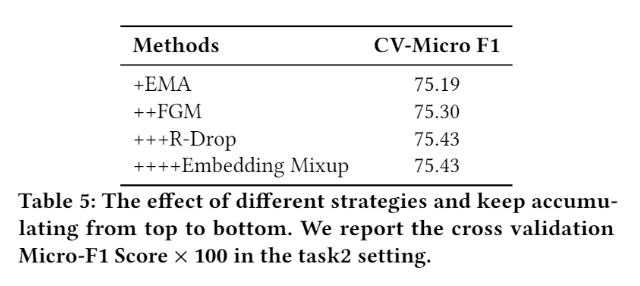
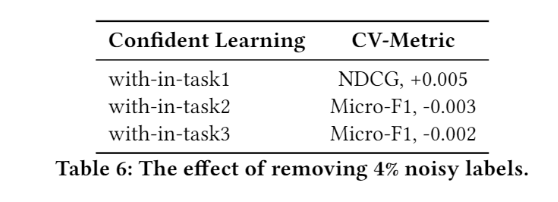
In this work, we use data augmentation, multi-task pre-training and several fine-tuning methods to imporve our model’s generalization and robustness.
We release the source code at GitHub - cuixuage/KDDCup2022-ESCI
Thanks All~ ![]()
Looking forward to more sharing and papers
[1] Shopping Queries Dataset: A Large-Scale ESCI Benchmark for Improving Product Search
[2] Multi-Task Deep Neural Networks for Natural Language Understanding
[3] Embedding-based Product Retrieval in Taobao Search
[4] Que2Search: Fast and Accurate Query and Document Understanding for Search at Facebook
🚀 Code Submission Round Launched 🚀
Almost 4 years agoI also have the same problem, it seems that the failures due to network fluctuations.
Describe the bug
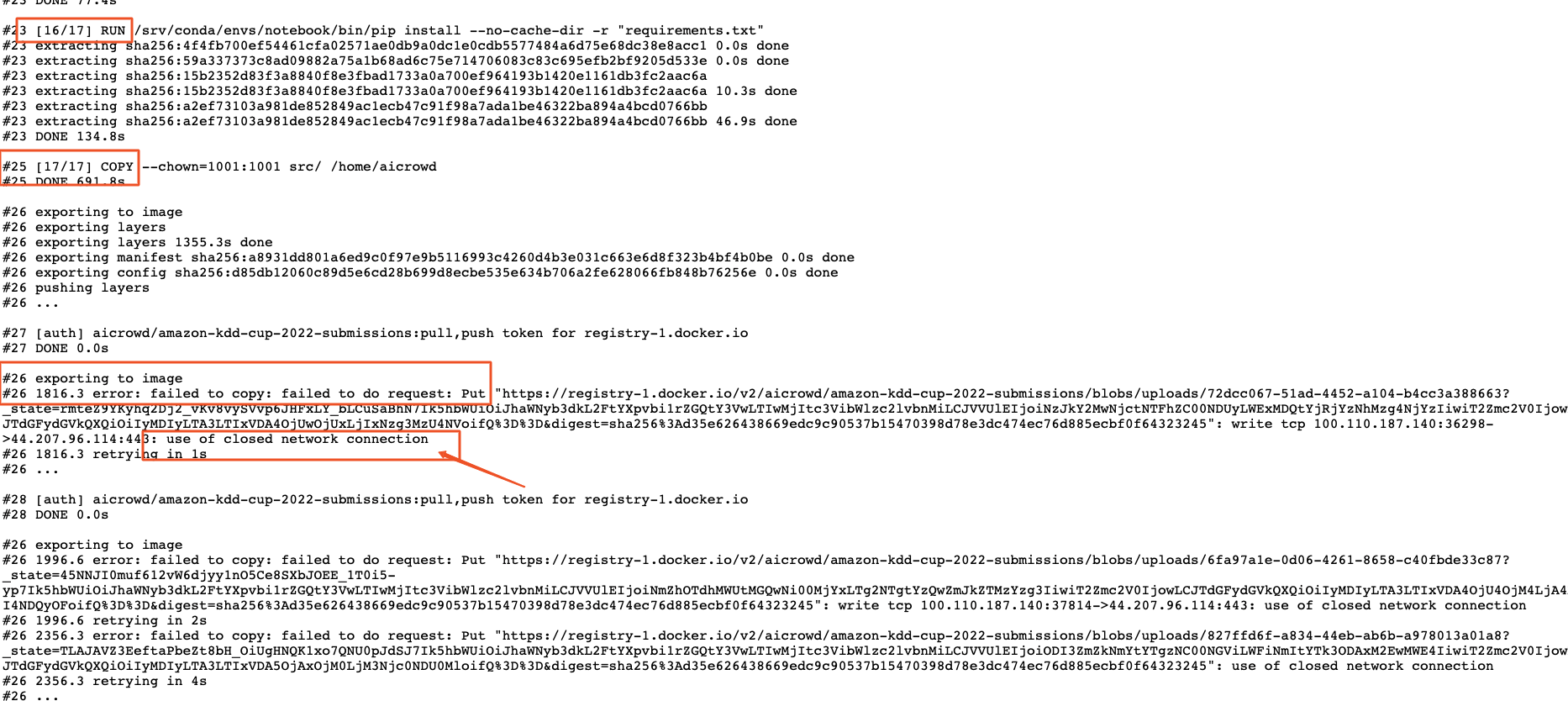
My submissions are :
submission_hash :
08bd285849b47afb73ec59993561b26baec9bbb1
submission_hash :95c28e3692ec2259650394218c679470ffcc95a8
submission_hash :70800c63ce568686f330dc1f848c4eda8e8ccf45
Screenshots
@mohanty @shivam
Could you please restart my submission? It seems to me that the request is in compliance with the rules.
(In this great game, no one wants to have any regrets. ![]() )
)
🚀 Code Submission Round Launched 🚀
Almost 4 years agoDuring the last day, I had some submissions waiting in the queue for hours.
Could you provide more machine resources to ensure that our submissions start running as soon as possible?
Best,xuange
🚀 Code Submission Round Launched 🚀
Almost 4 years agohi, the channel of pip source could be kept up to latest?
Describe the bug
when i used requirements.txt as this:
pandas==1.4.2
The error is
Status: QUEUED
…
Status: BUILDING
…
Status: FAILED
Build failed
Last response:
{
“git_uri”: “git@gitlab.aicrowd.com:xuange_cui/task_2_multiclass_product_classification_starter_kit.git”,
“git_revision”: “submission-v0703.09”,
“dockerfile_path”: null,
“context_path”: null,
“image_tag”: “aicrowd/submission:192070”,
“mem”: “14Gi”,
“cpu”: “3000m”,
“base_image”: null,
“node_selector”: null,
“labels”: “evaluations-api.aicrowd.com/cluster-id: 2; evaluations-api.aicrowd.com/grader-id: 68; evaluations-api.aicrowd.com/dns-name: runtime-setup; evaluations-api.aicrowd.com/expose-logs: true”,
“build_args”: null,
“cluster_id”: 1,
“id”: 3708,
“queued_at”: “2022-07-03T09:03:31.405604”,
“started_at”: “2022-07-03T09:03:43.673873”,
“built_at”: null,
“pushed_at”: null,
“cancelled_at”: null,
“failed_at”: “2022-07-03T09:07:34.352399”,
“status”: “FAILED”,
“build_metadata”: “{“base_image”: “nvidia/cuda:10.1-cudnn7-runtime-ubuntu18.04”}”
}
But when i used requirements.txt as this:
pandas==1.1.5
The debug log shows that I have completed successfully
Status: QUEUED
.
Status: BUILDING
…
Status: PUSHED
Build succeeded
Trying to setup AIcrowd runtime.
2022-07-03 09:01:35.781 | INFO | aicrowd_evaluations.evaluator.client:register:153 - registering client with evaluation server
2022-07-03 09:01:35.785 | SUCCESS | aicrowd_evaluations.evaluator.client:register:168 - connected to evaluation server
Phase Key : public_test_phase
Phase Key : public_test_phase
Progress ---- 3.609534947517362e-06
Progress ---- 0.7759706039473874
Writing Task-2 Predictions to : /shared/task2-public-64b9d737-1ec6-4ff6-843f-7bdcf17042b1.csv
Progress ---- 1
Screenshots

🚀 Code Submission Round Launched 🚀
Almost 4 years agohi ,I get an error when I make the second submission:
Describe the bug
Submission failed : The participant has no submission slots remaining for today. Please wait until 2022-07-03 08:51:17 UTC to make your next submission.
Expected behavior
A Team may make only five submission per task per 24-hour period. Challenge Rule URL.
Screenshots
1.Limited by the current number of commits, I may have only a few opportunities to test my prediction code.
2.I’m not familiar with repo2docker (especially the environment configuration),it makes me more worried about whether I can finish the competition before July 15th.
Is it possible to increase the number of submissions?
Best,
Xuange
The metrics in the leaderboard of task 2 & 3 seems strange
About 4 years agoIn multi-class, micro f1 == accuracy
And, I hope the ref url will help.
REF:
【Solution ZhichunRoad】 5th@task1, 7th@task2 and 8th@task3
Over 3 years agoThanks for the information, they are very helpful!
I used the mlm task as the basic pre-training task and did not remove it separately.
So I not sure whether the MLM Task works well.
But, I would like to provide some additional information.
As presented in some Domain pre-training Papers[1],using additional unlabeled datasets for pretraining can get good performance in most domains CV, NLP, etc. (I personally think the pre-training stage is essential.)
In the product_catalogue dataset, there are ~20w product meta info that do not appear in the public dataset (the training set & public test set).
To make the model “familiar with” this part of the data. Except for the MLM task, I can’t think of a better method…
[1] Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks
@yrquni @hsuchengmath @zhichao_feng
Looking forward to more discussions & ideas.