
⏰ The submission limit is now updated to 10 submissions per day!
📕 CPD Task 2 is now a shared task for 6th Workshop on NLP for Conversational AI.
📚 Resource for Task1 & Task2: Research Paper, Models and More📚 Resource for Task1 & Task2: Research Paper, Models and More
👥 Find teammates 💬 Share your queries
📕 Make your first submission with ease using the starter-kit.
🕵️ Introduction
Understanding rich dialogues often requires NLP systems to access relevant commonsense persona knowledge that grounds the dialogue. However, it is challenging to retrieve such relevant persona commonsense from knowledge bases, due to the complex contexts of real-world dialogues, and the implicit and ambiguous nature of commonsense knowledge. In this task, we are calling for commonsense persona knowledge linkers that can robustly identify relevant commonsense facts associated to speakers and listeners in dialogues.
📑 The Task
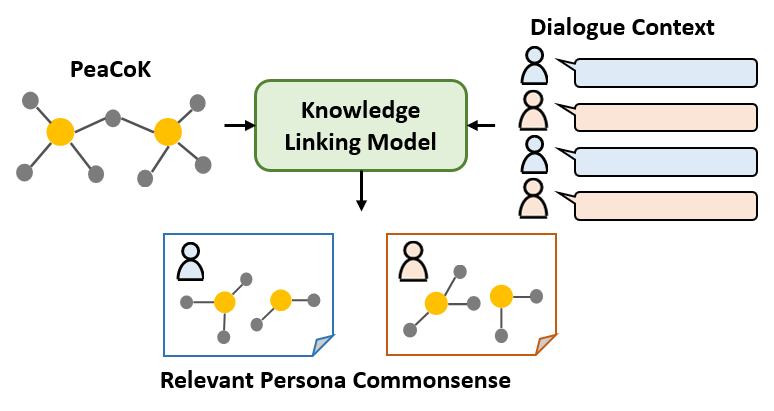
Note: We do not provide a training dataset, and participants may use any datasets which they want to use. We provide a baseline model, which can be tested on the ComFact benchmark, so that you can see what is the problem of this task.
💾 Evaluation Data
Format
The evaluation dataset contains a list of testing samples, each consists of three parts of data:
- dialogue context with window size 5: [ut-2, ut-1, ut, ut+1, ut+2], where ut is the central utterance in the selected context window, with surrounded two past dialogue utterances (ut-2, ut-1) and two future dialogue utterances (ut+1, ut+2). Utterances ut-2, ut and ut+2 are from the same interlocutor, while utterances ut-1 and ut+1 are from the other counterpart interlocutor. If a surrounding utterance is not available (e.g., if the context window is centered on the first dialogue utterance, then ut-2 and ut-1 will not be available), the corresponding data field will be filled with a space.
- persona commonsense fact: [head, relation, tail], where head describes a general persona, and tail describes a specific attribute associated to the persona via the relation (the set of relations is defined in the PeaCoK knowledge graph).
Note: each dialogue context can have up to 270 words (5 utterances in total), and each persona commonsense fact (persona-relation-attribute triple) can have up to 24 words.
Example
We provide some illustrative examples of the evaluation data.
Policy
The test set of the CPD challenge will be closed: participants will not have access to it, not even outside the challenge itself; this allows a fair comparison of all submissions. The set was created by Sony Group Corporation with the specific intent to use it for the evaluation of the CPD challenge. It is therefore confidential and will not be shared with anyone outside the organization of the CPD challenge.
👨🎓 Evaluation Metrics
Automatic Evaluation Metrics
The ranking will be displayed on the leaderboard based on the automatic evaluation results.
- F1 (main score for ranking)
- Accuracy (supplementary score)
We will evaluate submitted systems (models) based on the closed evaluation dataset we prepared for CPD challenge, and measure F1 and accuracy of the relevance classification results on the pairs of dialogue context and persona commonsense fact.
Note: Systems must be self-contained and function without a dependency on any external services and network access.
📕 Baselines
We provide an illustrative baseline model for this task, which is an entity linker trained on the ComFact benchmark, based on the DeBERTa (microsoft/deberta-v3-large) model. The entity linker separately discriminates the relevance of the fact’s head (persona) and tail (attribute) entities, and outputs the positive label (true) only if the head and tail entities are both relevant to the dialogue context. Our model checkpoint and evaluation scripts are available in the baseline model repository.
Our baseline model’s performance on the test set of CPD challenge:
- F1: 45.64
- Accuracy: 80.66
Note: The dataset and evaluation scripts used in our baseline model repository follow the format of ComFact benchmark. However, the dataset and evaluation formats required in our CPD challenge are different from the baseline model implementations, please refer to Evaluation Data and Submission Format for submitting your models.
✏️ Ready To Make Your Submission?
This task involves training AI to adeptly correlate dialogue with pertinent real-world knowledge, thereby enriching the informational and contextual quality of conversations.
Focusing on Binary Classification? If your model is proficient in discerning relevant from irrelevant information, this task is suitable for your research. Utilize our baseline model’s training dataset as a starting point.
Expertise in Knowledge Graphs? We encourage the development of models that can effectively associate knowledge segments with dialogue elements. We have prepared a set of potential knowledge-dialogue pairs for your AI to analyze and link appropriately.
Initiating Research in Knowledge Linking? For newcomers in this field, our “Baseline” section and the ComFact paper serve as comprehensive introductory resources. This task offers an excellent avenue to delve into the intricate interplay between AI and knowledge graphs.
✍️ Submission Format and Compute Constraints
Details of the submission format are provided in the starter kit.
You will be provided with conversation windows to classify, in a batch of upto 250 conversation windows. The size of the batch can vary slightly but will not exceed 250. For each conversation window, you need to make the classification. Each batch needs to be processed in 250 seconds. The number of batches will vary based on the challenge round.
Before running on the challenge dataset, your model will be run on the dummy data, as a sanity check. This will show up as the convai-validation phase on your submission pages. The dummy data will contain 5 conversations windows, your model needs to complete the validation phase within 250 seconds.
Your model will be run on an AWS g4dn.xlarge node. This node has 4 vCPUs, 16 GB RAM, and one Nvidia T4 GPU with 16 GB VRAM
📅 Timeline
The challenge will take place across in 3 Rounds which differ in the evaluation dataset used for ranking the systems.
- Warm-up Round : 3rd November, 2023
- Round 1 : 8th December, 2023 (23:59 UTC)
- Round 2 : 15th January, 2024 (23:59 UTC)
- Team Freeze Deadline: 8th March, 2024 (23:59 UTC)
- Challenge End: 15th March, 2024 (23:59 UTC)
🏆 Prizes
- 🥇 First place 5,000 USD
- 🥈 Second place 3,000 USD
- 🥉 Third place 2,000 USD
Please refer to the Challenge Rules for more details about the Open Sourcing criteria for each of the leaderboards to be eligible for the associated prizes.
📖 Citing the Dataset
If you are participating in this challenge or using the dataset please consider citing the following paper:
@inproceedings{gao-etal-2022-comfact, title = "{C}om{F}act: A Benchmark for Linking Contextual Commonsense Knowledge", author = "Gao, Silin and Hwang, Jena D. and Kanno, Saya and Wakaki, Hiromi and Mitsufuji, Yuki and Bosselut, Antoine", booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2022", year = "2022", pages = "1656--1675", }
📱 Challenge Organizing Committee
- Hiromi Wakaki (Sony)
- Antoine Bosselut (EPFL)
- Silin Gao (EPFL)
- Yuki Mitsufuji (Sony)
- Mengjie Zhao (Sony)
- Yukiko Nishimura (Sony)
- Yoshinori Maeda (Sony)
-
Keiichi Yamada (Sony)
Have queries, feedback or looking for teammates, drop a message on AIcrowd Community. Don’t forget to hop onto the Discord channel to collaborate with fellow participants & connect directly with the organisers. Share your thoughts, spark collaborations and get your queries addressed promptly.
 Continue with Google
Continue with Google
 Sign Up with Email
Sign Up with Email