
Problem Statements

Task 1: Commonsense Dialogue Response Generation
Commonsense Dialogue Response Generation

Task 2: Commonsense Persona Knowledge Linking
Commonsense Persona Knowledge Linking
🗓️ Challenge deadline is extended to 16th March, 2024 23:59 UTC.
⏰ The submission limit is now updated to 10 submissions per day!
✨ This challenge is a shared task of the 6th Workshop on NLP for Conversational AI 📕
📚 Resource for Task1 & Task2: Research Paper, Models and More
👥 Find teammates 💬 Share your queries
💻 Resources: Baseline Training Model 📕 Starter-kit 📓 Baseline
Welcome to the Commonsense Persona-grounded Dialogue (CPD) Challenge !
This challenge is an opportunity for researchers and machine learning enthusiasts to test their skills on the challenging tasks of Commonsense Dialogue Response Generation (Task1) and Commonsense Persona Knowledge Linking (Task2) for persona-grounded dialogue.
🕵️ Introduction
Research on dialogue systems has been around for a long time, but thanks to Transformers and Large Language Models (LLM), conversational AI has come a long way in the last five years, becoming more human-like. On the other hand, it is still challenging to collect natural dialogue data for research and to benchmark which models ultimately perform the best because there is no definitive assessment data or metrics, and the comparisons are often within a limited amount of models.
We contribute to the research and development of current state-of-the-art dialogue systems, by crafting high quality human-human dialogues for model testing, and providing a common benchmarking venue by hosting this CPDC 2023 competition.
The competition aims to see the best approach among state-of-the-art participant models on an evaluation dataset of natural conversation. The submitted systems will be evaluated on a new Commonsense Persona-grounded Dialogue dataset. To this end, we first created several persona profiles, similar to ConvAI2, with a natural personality based on a commonsense persona-grounded knowledge graph (PeaCoK†) newly released on ACL 2023, and allowing us to obtain naturally related persona sentences. Furthermore, based on that persona, we created a natural dialogue between two people and prepared a sufficient amount of dialogue data for evaluation.
The Commonsense Persona-grounded Dialogue (CPD) Challenge hosts one track on Commonsense Dialogue Response Generation (Task 1) and one track on Commonsense Persona Knowledge Linking (Task 2). Independent leaderboards are set for the two tracks, each featuring a separate prize pool. In either case, participants may use any learning data. In Task 1, participants will submit dialogue response generation systems. We will evaluate them on the prepared persona-grounded dialogue dataset mentioned above. In Task 2, participants will submit systems linking knowledge to a dialogue. This task is designed in the similar spirit of ComFact, which is released along with the published paper in EMNLP 2022. We will evaluate them by checking if the linking of persona-grounded knowledge can be judged successfully on the persona-grounded dialogue dataset.
† PeaCoK: Persona Commonsense Knowledge for Consistent and Engaging Narratives (ACL2023 Outstanding Paper Award)
✏️ GPU and Prompt Engineering Tracks
We provide two separate settings for participants to choose from, the GPU track and the Prompt Engineering Track.
GPU Track
In this track we provide participants with access to a single GPU with 24GB VRAM, this will allow them to fine tune and submit their own LLMs that are specific for this task.
Prompt Engineering Track
In the prompt engineering track, we provide participants with access to the OpenAI API. This will allow anyone to test their prompt engineering skills with a powerful LLM and combine it with advanced etrieval based methods to generate context.
📑 The Task
Task 1: Commonsense Dialogue Response Generation
🔗 Task 1: Commonsense Dialogue Response Generation
Participants will submit dialogue response generation systems. We do not provide a training dataset, and participants may use any datasets which they want to use. We provide a baseline model, which can be tested on the ConvAI2 PERSONA-CHAT dataset, so that you can see what the problem of this task is. We will evaluate submitted systems on the persona-grounded dialogue dataset. The dialogues in the evaluation dataset have persona sentences similar to the PersonaChat dataset, but the number of persona sentences for a person is more than five sentences. The major part of the persona is derived from the PeaCoK knowledge graph.

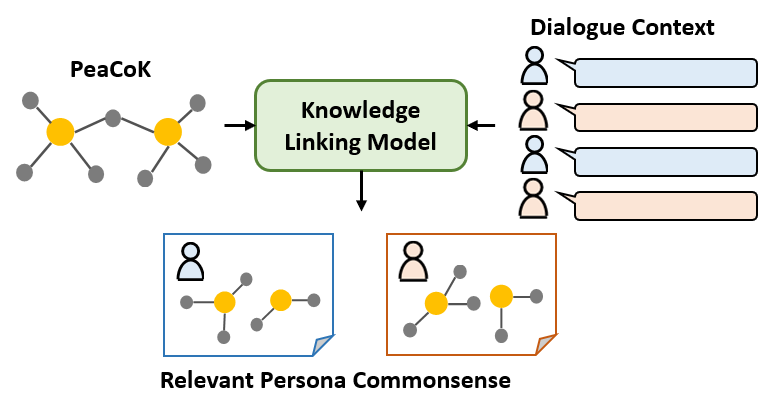
Task 2: Commonsense Persona Knowledge Linking
🔗 Task 2: Commonsense Persona Knowledge Linking
Participants will submit systems for linking knowledge to a dialogue. We don’t provide a training dataset and participants may use any datasets which they want to use. We provide a baseline model, which can be tested on the ComFact benchmark, so that you can see what is the problem of this task. We will evaluate submitted systems by checking if the linking of persona-grounded knowledge (PeaCoK) can be judged successfully on the persona-grounded dialogue dataset. Note that the persona statements are prepared in advance when creating a dialogue and the persona knowledge selected as a candidate for linking are completely independent.
📅 Timeline
The challenge will take place across in 3 Rounds which differ in the evaluation dataset used for ranking the systems.
- Warm-up Round : 3rd November, 2023
- Round 1 : 8th December, 2023 (23:59 UTC)
- Round 2 : 15th January, 2024 (23:59 UTC)
- Team Freeze Deadline: 8th March, 2024 (23:59 UTC)
- Challenge End: 15th March, 2024 (23:59 UTC)
🏆 Prizes
The prize pool is a total of 35,000 USD divided among the two tracks. Participating teams are eligible to win prizes in multiple leaderboards spread across both the tracks.
Task1: Commonsense Dialogue Response Generation
- 🥇 First place 15,000 USD
- 🥈 Second place 7,000 USD
- 🥉 Third place 3,000 USD
Task2: Commonsense Persona Knowledge Linking
- 🥇 First place 5,000 USD
- 🥈 Second place 3,000 USD
- 🥉 Third place 2,000 USD
Please refer to the Challenge Rules for more details about the Open Sourcing criteria for each of the leaderboards to be eligible for the associated prizes.
🔗 Quick Links
-
Task1 Baseline model: https://github.com/Silin159/PersonaChat-BART-PeaCoK
-
Task2 Baseline model: https://github.com/Silin159/ComFact-Relation-Agnostic
-
PeaCoK: PeaCoK: Persona Commonsense Knowledge for Consistent and Engaging Narratives - ACL Anthology (ACL2023 Outstanding Paper Award)
-
ComFact: ComFact: A Benchmark for Linking Contextual Commonsense Knowledge - ACL Anthology
📖 Citing the Dataset
If you are participating in this challenge or using the dataset please consider citing the following paper:
Task1 Dataset: PeaCoK
@inproceedings{gao-etal-2023-peacok,
title = "{P}ea{C}o{K}: Persona Commonsense Knowledge for Consistent and Engaging Narratives",
author = "Gao, Silin and
Borges, Beatriz and
Oh, Soyoung and
Bayazit, Deniz and
Kanno, Saya and
Wakaki, Hiromi and
Mitsufuji, Yuki and
Bosselut, Antoine",
booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
year = "2023",
pages = "6569--6591",
}
Task2 Dataset: ComFact
@inproceedings{gao-etal-2022-comfact,
title = "{C}om{F}act: A Benchmark for Linking Contextual Commonsense Knowledge",
author = "Gao, Silin and
Hwang, Jena D. and
Kanno, Saya and
Wakaki, Hiromi and
Mitsufuji, Yuki and
Bosselut, Antoine",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2022",
year = "2022",
pages = "1656--1675",
}
📱 Challenge Organizing Committee
-
Hiromi Wakaki (Sony)
-
Antoine Bosselut (EPFL)
-
Silin Gao (EPFL)
-
Yuki Mitsufuji (Sony)
-
Mengjie Zhao (Sony)
-
Yukiko Nishimura (Sony)
-
Yoshinori Maeda (Sony)
-
Keiichi Yamada (Sony)
Have queries, feedback or looking for teammates, drop a message on AIcrowd Community. Don’t forget to hop onto the Discord channel to collaborate with fellow participants & connect directly with the organisers. Share your thoughts, spark collaborations and get your queries addressed promptly.
Participants










































Leaderboard
| 01 |

|
4.000 |
| 01 |
|
4.000 |
| 01 |
|
4.000 |
| 02 |
 kcy4
kcy4
|
5.000 |
| 02 |
kcy4
|
5.000 |