
Location
 CA
CA
Badges
Activity
Challenge Categories
Challenges Entered

What data should you label to get the most value for your money?
Latest submissions

Machine Learning for detection of early onset of Alzheimers
Latest submissions
See All| graded | 145471 | ||
| graded | 145458 | ||
| graded | 145420 |

Play in a realistic insurance market, compete for profit!
Latest submissions
See All| graded | 125508 | ||
| graded | 125497 | ||
| graded | 125493 |

5 Problems 21 Days. Can you solve it all?
Latest submissions
See All| graded | 124827 | ||
| graded | 124826 | ||
| graded | 124825 |

5 Puzzles 21 Days. Can you solve it all?
Latest submissions

5 Puzzles, 3 Weeks | Can you solve them all?
Latest submissions

Predict the winner through prior chess moves
Latest submissions
See All| graded | 124827 | ||
| graded | 124826 | ||
| graded | 124825 |
| Participant | Rating |
|---|
| Participant | Rating |
|---|
ADDI Alzheimers Detection Challenge

Do you trust your Leaderboard Score?
Almost 5 years agoHi @moto ,
Just curious, your best submission (the one kept in the private LB) is it Python or R? 
Motivation from the submission history
Almost 5 years agoHi @Johnowhitaker,
Thank you for the graph. Did you use 3-digits submissions logloss? My feeling is that the shape will be quite different with no rounded results.
And it made me think: what would happen if more than 10 participants reach the top? (as there are 10 prizes).
Fictive example:
- 1 — 0.590
- 2 — 0.594
- 3 — 0.598
- 4 to 8 — 0.600
- 9 to 12 — 0.601
Random variable(s)
Almost 5 years agoHi,
I edited my notebook by adding new sections, and one of them is “Random”  .
.
When I build a model, I always add a random variable (from uniform distribution) to detect useless variables. I consider that all variables ranked under the random one are explaining noise. So I remove them  , and run a simpler and faster model
, and run a simpler and faster model  . As these variables were rarely used by the model, predictions and performances are very similar (but always a little lower
. As these variables were rarely used by the model, predictions and performances are very similar (but always a little lower  ). But the model is easier to implement.
). But the model is easier to implement.
Here, the rank is 39 !
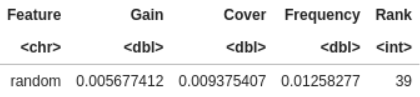
It mean I should remove a lot of variables  . I tested it: 2 successive models, one with all variables (LB logloss: 0.6136) and one with only 38 variables (LB logloss: 0.6147). Very similar …
. I tested it: 2 successive models, one with all variables (LB logloss: 0.6136) and one with only 38 variables (LB logloss: 0.6147). Very similar …
My feeling, and it was already discuss in a different post, is that random play a strong part in our submissions. Results and ranks will (randomly?) change on the 40% hidden dataset.
What do you think ? ![]()
Not able to edit an existing notebook
Almost 5 years agoI just tested with “upload” and it worked!
Thank you.
I could now edit and add some new stuffs in the notebook.
Not able to edit an existing notebook
Almost 5 years agoI tested both.
Initially, using colab link didn’t work, that’s why I tested to download the file and upload it (and it worked). But now that I want to edit it, even the upload way doesn’t work. I will try today again.
Do you trust your Leaderboard Score?
Almost 5 years agoI hope you’ll invite me for a game if you win the playstation
Do you trust your Leaderboard Score?
Almost 5 years agoThank’s. Don’t hesitate to like it  , this will increase my chance for the Community Price, even if I participated lately.
, this will increase my chance for the Community Price, even if I participated lately.
For the R notebook, you have to install R in order to see “R kernel” at the top right of your notebook.
Not able to edit an existing notebook
Almost 5 years agoHi,
I shared a notebook yesterday, by uploading a .ipynb file downloaded from Google Colab. It edited this Colab, download it again, and try to edit the notebook, but I got the following error:
“Unable to process the notebook. Check the file and try again”.
I tried with the file that worked yesterday, and I got the same error. I tried several time, on Edge and Chrome.
Do you know what could happen? Thanks in advance.
Add a 4th class?
Almost 5 years agoYou probably noticed in the dataset some “normal” observations with very strange clocks  (less than 4 digits, no hands, etc.). In the training dataset, it’s almost 50% of “normal” observations.
(less than 4 digits, no hands, etc.). In the training dataset, it’s almost 50% of “normal” observations.
One assumption is that these patients are affected by a disease  which is not Alzheimer (Parkinson, Lewy-body, …), so considered as “normal” in our classification puzzle.
which is not Alzheimer (Parkinson, Lewy-body, …), so considered as “normal” in our classification puzzle.
Sharing this particularity to the model  could be helpful … I tried to split the main class in 2:
could be helpful … I tried to split the main class in 2:
- “true normal”
- “anormal”
What do you think of that? ![]()
Do you trust your Leaderboard Score?
Almost 5 years agoInteresting discussion!
I was working on a notebook that shares some throughs similar of yours @etnemelc . I am convinced that most of the time I managed to improve my leaderboard score (from 0.610 to 0.606), I was overfitting this specific dataset. The difference are so little, it could clearly be noise, especially on “small” datasets like those.
I agree with you @michael_bordeleau, I wonder if observations came from the same source. I find the split in number of observations (33,000 for the train, 362 for test and 1,500 for leaderboard) really intriguing … is it to make the competition harder, or is there a reason behind? I’m curious to see.
Validation Set
About 5 years agoYou can.
https://discourse.aicrowd.com/t/combination-of-train-and-validation-set-and-even-test-set/5696
👋 Welcome to the ADDI Alzheimer's Detection Challenge!
About 5 years agochange your username for “bordeleau_michael” … 
FastAI Starter Notebook and Class Balance
About 5 years agoExcellent notebook, thank you for sharing!
One point that makes me think, is the size of test dataset (only 362 obs.), meaning significant variability of the criteria. Some logloss of your notebook are so closed, they could be considered as similar, with no guarantee order will stay the same on leaderboard. I experimented it, with a model that decrease test dataset logloss (while never seen it), but increase leaderboard one … 
My feeling is that current top 10 are the ones, as @no_name_no_data said, that slight overfit leaderboard dataset.
I am curious to see our this will evolve, I hope some participants will found tricks that generally reduce logloss.
Not able to get starter notebook
About 5 years agoHi,
I followed the instructions of several discussions, and the first lines of code seem to work (no warning nor error). I managed to download aicrowd.R file, to download and load R libraries, load the datasets and made some explorations.
But I got an error when I tried to linked with my Aicrowd account.
aicrowd_login(AICROWD_API_KEY)
running command … had status 1
I copy-paste directly from my aicrowd page, so I don’t think I made an error. Do you know what could be the problem?
Load model
About 5 years agoHi,
Just to be sure I correctly understand: we don’t have access to the test dataset (the one used for Leaderboard, that contains 1,473 rows), even its features, right? Our model will be loaded and applied on it?
Thank you.
Did anyone get R to work?
About 5 years agoHi,
I followed the instructions shared by @michael_bordeleau, and the first lines of code seem to work (no warning nor error). I managed to download aicrowd.R file.
I can’t reach CRAN url to download a library, but I can load already installed ones, load the datasets and made some explorations.
But I got an error when I tried to linked with my Aicrowd account.
aicrowd_login(AICROWD_API_KEY)
running command … had status 1
I copy-paste directly from my aicrowd page, so I don’t think I made an error. Do you know what could be the problem?
Common issues for Windows users
About 5 years agoHi,
I managed to open the R starter notebook (in Jupyter, on Windows VM), but I got a warning message at the first line of code, which is:
cat(system('curl -sL …
I didn’t edit the code, just click on “Run”.
The warning is:
aicrowd.R had status 6
is it normal? it generates an error at the next chunk, when trying to source this aicrowd.R file.
Not able to get starter notebook
About 5 years agoHi,
I am on a Windows VM, I managed following the first steps :
- open Linux VM to manually copy train.csv and valid.csv in the folder “files/”
- install Anaconda
- change proxy
- install r packages (I would like to work with R)
But I can’t manage the next step which is to copy the starter notebook. I get the following error:
‘cp’ is not recognized as an internal or external command
Do you know what I missed?
Thank you in advance,
AI Blitz #6
📝 Explained, by Community | $100 x 2 Cash Prizes
About 5 years agoHi all,
Do you have updates on these Community prices?
@vrv
Notebooks
-
 R you normal? (explore datapoints + xgboost training 0.606) Challenges reflections and r xgboost approachdemarsylvain· Almost 5 years ago
R you normal? (explore datapoints + xgboost training 0.606) Challenges reflections and r xgboost approachdemarsylvain· Almost 5 years ago -
 Work in progress about video transcriptions Capture images from video and compare them to identify movesdemarsylvain· About 5 years ago
Work in progress about video transcriptions Capture images from video and compare them to identify movesdemarsylvain· About 5 years ago -
 Learn from started code Using started codes shared by admin and improve accuracy for the image classifier problemsdemarsylvain· Over 5 years ago
Learn from started code Using started codes shared by admin and improve accuracy for the image classifier problemsdemarsylvain· Over 5 years ago
Sharing Best submissions
Almost 5 years agoHi all,
This competition was great
 , and even it’s over, i’m still curious about what other participants have done
, and even it’s over, i’m still curious about what other participants have done 
 . Is your best submission (kept in the private LB) the one you expected? Do you think you find a feature others didn’t think about? Did you test ensemble models or other approaches?
. Is your best submission (kept in the private LB) the one you expected? Do you think you find a feature others didn’t think about? Did you test ensemble models or other approaches?
Mine (20th position) is a quite simple R xgboost with:
and weightings giving the following distribution (using all observations of both training and test datasets):
About feature engineering
 , I gather several variables with mean and sum, like most of you probably. Maybe one feature (with good ranking) we never talk about it, is the ratio between the minute hand and the average distance from centre of the digits:
, I gather several variables with mean and sum, like most of you probably. Maybe one feature (with good ranking) we never talk about it, is the ratio between the minute hand and the average distance from centre of the digits:
ratio_hand_Xi = minute_hand_length / mean_dist_from_cen__Kudos to the organizers, and congrats to all winners and contributors!