
Location
 CA
CA
Badges
Activity
Challenge Categories
Challenges Entered

Audio Source Separation using AI
Latest submissions

Latest submissions
See All| graded | 151396 | ||
| failed | 151375 | ||
| failed | 151371 |
| Participant | Rating |
|---|---|
 Chen_Wei_Te
Chen_Wei_Te
|
0 |
| Participant | Rating |
|---|
Music Demixing Challenge ISMIR 2021

Making new music available for demixing research
Over 4 years agoI recently created a Python loader, similar to sigsep-mus-db, for the OnAir dataset: https://github.com/OnAir-Music/onair-py
It maps the custom stems into the 4 musdb targets (drums/bass/vocals/other) as best as I could manage. Some cases were tricky, e.g. LoFi hiphop which has faint ambient vocals, and no singing.
Making new music available for demixing research
Over 4 years agoI’m about to release 2 new tracks, and I’m now making use of the GitHub discussions feature on the main repo.
Until now I have been releasing the stems in the same way the artists give them to us (not consistent). Here’s a GitHub discussion to talk about potentially choosing a better, more consistent stem format: https://github.com/OnAir-Music/OnAir-Music-Dataset/discussions/3
Examples are the 4 targets of MUSDB18-HQ, etc. Collaborators are welcome! (I can’t decide this on my own)
Making new music available for demixing research
Over 4 years agoAfter a slow start, we now have 7 full tracks with stems available in the V2 version of the zip. Going forward new stems will arrive as soon as the tracks are published on Spotify, and we anticipate many more to come.
The GitHub release method with LFS seems to be appropriate for now.
Making new music available for demixing research
Over 4 years agoI went ahead and created the first upload: https://github.com/OnAir-Music/OnAir-Music-Dataset
There is only one track/stem set for now. But there will be more coming!
Better sliCQ Transform by Schörkhuber et al 2014
Over 4 years ago@faroit
I recall in the presentation, when I showed the ragged time-frequency resolution of the sliCQT:
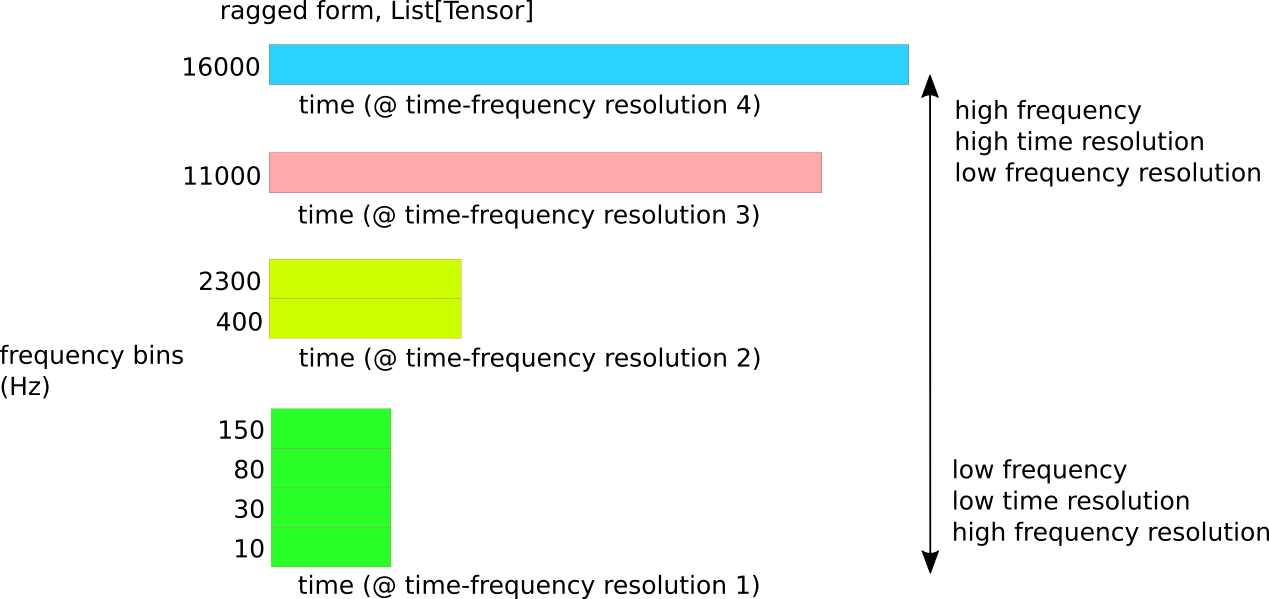
You asked if I tried interpolation.
The next evolution of the NSGT/sliCQT seems to be in this paper: https://www.researchgate.net/publication/274009051_A_Matlab_Toolbox_for_Efficient_Perfect_Reconstruction_Time-Frequency_Transforms_with_Log-Frequency_Resolution
Temporal alignment can be easily achieved by applying a common subsampling factor for all frequency bins k ∈1,…,K. That is, only the highest frequency channel is critically sampled and all other channels are subsampled with the same rate (we refer to this as full rasterization).
I believe rasterization is in the same vein as the interpolation you mentioned. I think implementing these Schörkhuber et al 2014 ideas into the NSGT library would give us the next evolution of a better sliCQT for music demixing.
Oracle baselines
Over 4 years agoVery nice, thanks. On another note, the “mixed-phase” oracle I was talking about above seems to have some mentions in literature as the “noisy phase”:
When estimating a time-frequency (T-F) mask that modifies the
mixture signal magnitude and uses the noisy mixture phase for
resynthesis, the phase-sensitive mask [2] can help compensate
for these noisy phase errors.
For a mask-based source separation approach, a easy and very common way to deal with phase is to just copy the phase from the mixture! The mixture phase is sometimes referred to as the noisy phase. This strategy isn’t perfect, but researchers have discovered that it works surprisingly well, and when things go wrong, it’s usually not the fault of the phase.
Since “noise” seems to come from speech demixing (speech + noise), I still prefer the term “mix-phase” for the music demixing case, since interfering musical instruments are not noise, but music!

Town Hall Practice Session
Over 4 years agoHiya - will the recording be uploaded to the YouTube AICrowd channel? https://www.youtube.com/channel/UCUWbe23kxbwpaAP9AlzZQbQ
Making new music available for demixing research
Over 4 years agoHello again!
I have a friend who created a project for recording royalty-free music, for use in live streaming (e.g. game streaming like Twitch.tv). The artists are paid but the music is open. Here are the links to the project:
- https://www.instagram.com/theonair.music/
- https://open.spotify.com/artist/7IYLENV1pGGPvL6wkyl7t5
- https://open.spotify.com/album/0Rbbl2SNe3ugla8z5m9S2P?si=EgkmhXEpTS6hQWnMQHrg_A&dl_branch=1&nd=1
I described the MDX to him, and he’s excited to also share the stem files from his project, free and open for all demixing and music research.
I’ve never created an academic dataset before - what sort of steps should I follow to ensure we do this properly? My first thoughts are to upload a zip file on a static GitHub pages website.
I believe as the project grows, the zip file of this dataset will grow to contain the new stems (and I’ll probably periodically change the zip file to include the new tracks).
Maybe I can call it the “OnAir.Music-stems-v1”, v2, v3, etc.
Ask your questions on the townhall presentation for Improved Demucs here
Over 4 years agoCongrats on the impressive performance in both leaderboards!
Surpassing the IRM means that you’re essentially surpassing the limitations of time-frequency uncertainty in the STFT, right?
Making my "music-demixing-challenge-starter-kit" submission repo public
Over 4 years agoHello,
So I already made my network public in a separate, cleaner GitHub repository.
However, I also want to make public the music-demixing-challenge-starter-kit repo, where I made 30 submissions to AICrowd, with the tags and Git-LFS storage for each of my submissions, etc.:
Is there any issue with my open-sourcing my starter kit repo? I think the only special AICrowd-GitLab-specific-file info is in the aicrowd.json file, but there is no API key or secret token or anything:
sevagh:music-demixing-challenge-starter-kit $ cat aicrowd.json
{
"challenge_id": "evaluations-api-music-demixing",
"grader_id": "evaluations-api-music-demixing",
"authors": [
"sevagh"
],
"description": "Modified Open-Unmix Separation model",
"external_dataset_used": false
}
🎉 The final leaderboard is live
Almost 5 years agoThanks!
Is this invite-only? https://github.com/mdx-workshop/submissions21 Or will it be public in the future?
🎉 The final leaderboard is live
Almost 5 years agoA question about the ISMIR paper. So I thought the ISMIR deadline is finished. Is the MDX workshop call for papers separate from the ISMIR 2021 paper submissions?
🎉 The final leaderboard is live
Almost 5 years agoAwesome challenge. Will MXDB21 be released as the “next gen” evolution of open demixing datasets?
The subject of the last town hall was how MUSDB18-HQ is small and it’s potential has been tapped out.
UMX iterative Wiener expectation maximization for non-STFT time-frequency transforms
Almost 5 years agoNow that I have open-sourced my code, here is the sliCQ Wiener/EM stuff:
- Square matrix of jagged/ragged list of Tensor by frequency bin: https://github.com/sevagh/xumx-sliCQ/blob/main/xumx_slicq/model.py#L300
- A few extra lines of flattens/permutes/reshapes to make it look like an STFT in the EM function: https://github.com/sevagh/xumx-sliCQ/blob/main/xumx_slicq/filtering.py#L191
- After Wiener/EM, undo the flattens/permutes/reshapes, and turn matrix back into jagged/ragged sliCQ: https://github.com/sevagh/xumx-sliCQ/blob/main/xumx_slicq/model.py#L321
Training Times
Almost 5 years agoOooh, I had no idea they stored some copies of UMX/XUMX: https://github.com/asteroid-team/asteroid/tree/master/egs/musdb18
Alternative download mirror for MUSDB18-HQ
Almost 5 years agoMy tone was probably more rude than necessary - sorry about that. I checked with some friends who reported 1000-4000kbps, so closer to what you got.
Perhaps I was having bad luck the other day.
Training Times
Almost 5 years agoedit Looks like error might be on my end. X-UMX needs some extra NNabla initialization done before the separate() function.
Since you seem to be working on X-UMX. Were you able to use the NNabla pre-trained X-UMX model to run inference successfully?
Right now I’m just trying to privately run a comparison of pretrained UMX vs. pre-trained X-UMX vs. my own model for this competition.
I have downloaded this pretrained model: https://nnabla.org/pretrained-models/ai-research-code/x-umx/x-umx.h5
I tried both the spleeter copy of the code, and the Sony original:
Also I filed the following issue on the Sony repo: https://github.com/sony/ai-research-code/issues/26
The prediction is all 0s for the X-UMX pretrained model, and I wonder what I’m doing wrong.
Alternative download mirror for MUSDB18-HQ
Almost 5 years agoZenodo is hit or miss. Today, I can’t get anything above 20kbps - as a result, I won’t be able to download MUSDB18-HQ feasibly any time this week or month.
(luckily I already have a copy that I used for the competition. I just wanted to redownload it on a different computer)
Can researchers consider hosting MUSDB18-HQ in a more accessible location? I don’t understand how a 21GB file is difficult to download in 2021. Just throw it in an S3 bucket somewhere. (I wouldn’t because I don’t want to violate copyrights or attribution etc.)
Is the submission process still open?
Over 4 years agoHello! I had some new ideas in 2022 and wanted to evaluate my system against the MDX21 DB. In my submission, I get the following error:
Is the MDX evaluation suspended for 2022? I was under the impression it would be kept open for a while.