AI, Crowd-Sourced: Computer Vision for Beginners
 By
aryankargwal
By
aryankargwal

In this latest series, we guide you on how you can start learning skills for various machine learning fields through hands-on problem-solving. Through this article, you’ll uncover a plethora of datasets and ML tasks that will launch you into this field!
In this segment, we are going through some of the beginner-friendly Computer Vision challenges hosted on AIcrowd. The challenges, along with the intricate discourse discussions and community contributions will simplify your learning process!
Computer vision is the field of science that trains computers to deal with visual information. The ideal aim for computer vision is to ultimately achieve all the tasks our visual system enables us to do.
In recent years, Machine Learning, especially Deep Learning, has transfigured computer vision by introducing various neural network architectures. These architectures are essentially different orientations of artificial neurons stacked together that can capture, understand, and interpret information from visual data that was impossible before.
Let us look into some computer vision challenges available on our platform.
🐍 SNAKE: Venomous Snake Classification

With yearly cases of snakebites ranging over 5 million (Williams et al., 2019) taking place worldwide, administrating immediate healthcare has become a strenuous task. Due to a lack of expert opinion from a herpetologist, in almost 50% of these cases (Bolon et al., 2020), the venomous nature of the snake isn’t identified.
As a joint venture between AIcrowd and AI for Good - ITU, SNAKE served as our very own attempt at providing a platform and dataset for the fellow community to devise a solution to this very issue using Machine Learning. For this challenge, participants are required to perform binary classification on a given set of data to verify whether a snake is venomous or not, using an image.

The starter kit for the challenge provides the participants with an optimized implementation of ResNet-128. ResNet is a modern take on the classic Convolutional Neural Networks, by bringing in jump connections among subsequent layers, these connections with previous layers help defeat the degradation that happens to the input with the huge number of layers.
This might make you think, “How will I train such a deep layered neural network for my classifier?”, well we have an answer. Transfer Learning, a machine learning method used to reuse training weights from a certain task to another. PyTorch and Keras provide numerous weights for such heavy CNNs which you may use as a starting point in your own classifier.
What CNN architecture did you use? Let us know in the comments!🧐
😷 MASKD: Real-Time Mask Detection

During the times of the pandemic, of all the methods implemented, face masks have proven to be the best precautionary method against transmission. However, with the world coming back to its normal pace, making sure that masks are being worn has become a task that requires a robust and optimized solution. Such solutions can help automate and ensure that masks are being worn at airports and workplaces with minimal human monitoring.

MASKD was introduced to the participants as a puzzle in the AI Blitz⚡2, our very own segment of fortnight-long marathons of interesting AI puzzles. This puzzle requires the participants to come up with models that are capable of detecting the location of masked faces in an image as well as the location of unmasked faces in the image.

This task can be tackled as a classic object detection task using Deep Learning to localize the location of masks. To kickstart the challenge, the AIcrowd team provides the participants with a starter kit. The implementation uses Mask RCNN, a deep neural network aimed to solve instance segmentation problems, i.e. localization of different objects in an image. Introduced by Facebook AI Research in 2017, the architecture can locate and give bounding boxes to multiple objects in an image in real-time running at about 5fps.
Seeing the efficiency of our starter kit might make you think, “World does not move at 5fps, will this system work in a real-life situation?”. Earlier participants and winners were seen utilizing new architectures like YOLO and its variants which are able to detect objects at a staggering 150fps.
How does your architecture perform against our dataset!💪🏼
🌊 LNDST: Detect water bodies from satellite Imagery

Due to global warming and the adverse effect it has on aquatic life, it has become an essential challenge for the modern world to map changes in water levels. Using satellite imaging for mapping water bodies not only helps us monitor global warming but also flood risks in prone areas.
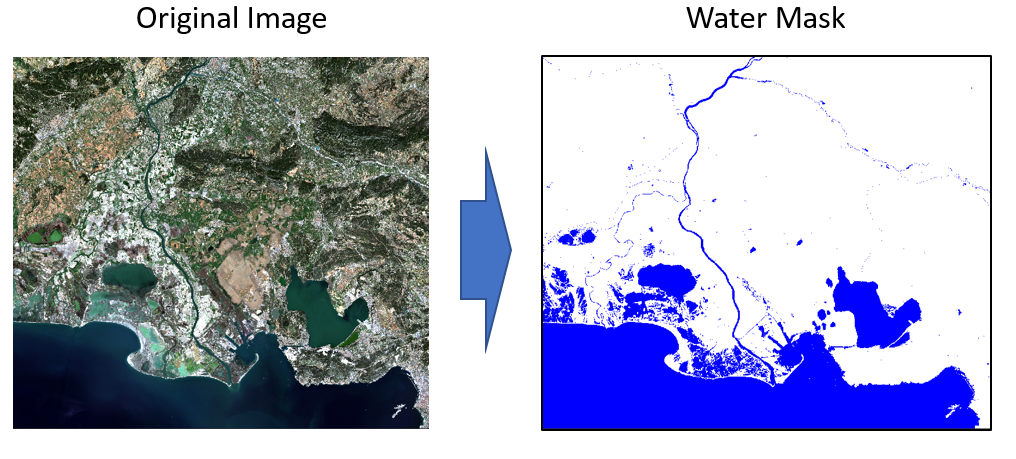
LNDST, short for Land Satelite is a challenge that aims to identify water bodies using satellite images.
Treating the prompt as an image segmentation task, we can identify changes in water levels. Image segmentation is the task of assigning different classes to different “segments” or clusters of pixels based on their characteristics. The task simply makes the image easier to analyze by putting masks on these various classes.

AIcrowd provides the participants with a starter kit. The kit uses UNET architecture for semantic segmentation of the dataset to localize water bodies. UNET architecture works on an encoder-decoder system. The encoder segment is just a traditional stack of convolutional and max-pooling layers, which are used to capture the context in the image. The decoder segment is a symmetric expanding path that enables precise localization that in turn allows Image Segmentation.
Feeling stuck? Check out one of the top scorers Ashwin Ramesh explain how he tackles this challenge by building upon our starter kit and using ResNet as the encoder for his UNET implementation in this blog.
What do you think is the most important ML field? Which topic do you want to explore next on AIcrowd? Comment below or tweet us @AIcrowdHQ to let us know!
Want to read more? ⬇️
Chapter 2: Natural Language Processing for Beginners
Chapter 3: Machine Learning For Beginners
Comments
You must login before you can post a comment.
You may also like...

 snehananavati
snehananavati