
⏰ The submission limit is now updated to 10 submissions per day!
📕 CPD Task 1 is now a shared task for 6th Workshop on NLP for Conversational AI.
📚 Resource for Task1 & Task2: Research Paper, Models and More
💻 Resources: Baseline Training Model 📕 Starter-kit 📓 Baseline
🕵️ Introduction
To sustain coherent and engaging conversations, dialogue agents must consider the personas of listeners to produce utterances that cater to their interests. They must also maintain consistent speaker personas, so that their counterparts feel engaged in a realistic conversation. However, achieving this persona alignment requires understanding the inter-connected interests, habits, experiences, and relationships of various real-word personas, and leveraging them effectively to robustly and believably engage in conversations. In this task, we are calling for dialogue response generation systems that can make good representation and incorporation of personas grounded on commonsense.
📑 The Task
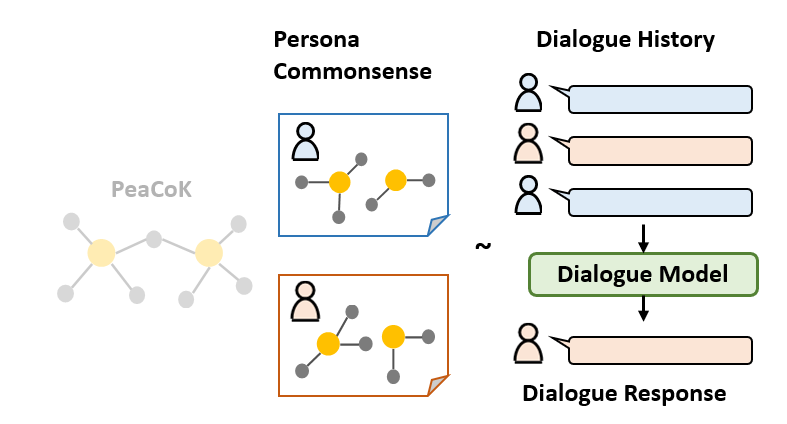
Two interlocutors are first assigned their background profiles that describe their personas in the dialogue. Each background profile contains basic information (e.g., name, age, etc.) and commonsense persona descriptions distilled from the PeaCoK† knowledge graph. Based on the assigned personas of two interlocutors, the task is to develop a dialogue model that generates one (orange) interlocutor’s response to his/her (blue) counterpart, given the dialogue history between these two interlocutors. The generated response should have good consistency with the dialogue history and persona backgrounds, and should also show good self persona expression and engagement with the counterpart.
Note: We do not provide a training dataset, and participants may use any datasets which they want to use. We provide a baseline model, which can be tested on the ConvAI2 PERSONA-CHAT dataset, so that you can see what the problem of this task is.
† PeaCoK: Persona Commonsense Knowledge for Consistent and Engaging Narratives (ACL2023 Outstanding Paper Award)
GPU and Prompt Engineering Tracks
We provide two separate settings for participants to choose from, the GPU track and the Prompt Engineering Track.
GPU Track
In this track we provide participants with access to a single GPU with 24GB VRAM, this will allow them to fine tune and submit their own LLMs that are specific for this task.
Prompt Engineering Track
In the prompt engineering track, we provide participants with access to the OpenAI API. This will allow anyone to test their prompt engineering skills with a powerful LLM and combine it with advanced etrieval based methods to generate context.
💾 Evaluation Data
Format
The evaluation dataset contains a list of testing samples, each consists of three fields of data:
- persona A: background profile of the counterpart interlocutor that the dialogue model generates response to, which contains a list of persona statements. Note that persona A will be invisible (i.e., replaced by an empty list) in real evaluation data, to simulate the real-world situation that the persona of counterpart is unknown.
- persona B: background profile of the interlocutor whose response is supposed to be generated by the dialogue model, with the same structure as persona A.
- dialogue: dialogue history consisting of multiple utterances from two interlocutors, each dialogue utterance consists of two fields of data:
- persona_id: indicator of which interlocutor this utterance is from (A or B)
- text: the specific content of the utterance from the indicated interlocutor
Note: each background profile can have up to 19 persona statements and up to 187 words, and each dialogue history can have up to 13 history utterances and up to 950 words.
Example
We provide an illustrative example of the evaluation data.
Policy
The test set of the CPD challenge will be closed: participants will not have access to it, not even outside the challenge itself; this allows a fair comparison of all submissions. The set was created by Sony Group Corporation with the specific intent to use it for the evaluation of the CPD challenge. It is therefore confidential and will not be shared with anyone outside the organization of the CPD challenge.
👨🎓 Evaluation Metrics
Automatic Evaluation Metrics
The ranking will be displayed on the leaderboard based on the automatic evaluation results.
- Word-level F1 (main score for ranking)
- Cumulative 4-gram BLEU (supplementary score)
We will evaluate submitted systems (models) based on the closed evaluation dataset we prepared for CPD challenge, and measure word-level F1 and cumulative 4-gram BLEU (Papineni et al., 2002) of the generated responses compared to the references created by human interlocutors.
Note: We provide standard implementations of our evaluation metrics in metrics.py.
Automatic metrics are not fully reliable for evaluating dialogue systems (Liu et al., 2016; Novikova et al., 2017), so we will also conduct human evaluations on the dialogue responses. However, human evaluation cannot be conducted for all submitted systems because of its heavy workload. Therefore, we only make pairwise comparisons between the top several team systems selected by automatic evaluation, based on their generated responses to randomly sampled dialogue histories.
Human Evaluation Criterias
Only the top several systems selected by the automatic evaluation will be judged via a human evaluation.
- Fluency: whether the response is fluent and understandable.
- Consistency: where the response is consistent with the dialogue history.
- Engagement: whether the response is engaging and interesting.
- Persona Expression: whether the response demonstrates persona information related to the interlocutor’s profile.
Note: Systems must be self-contained and function without a dependency on any external services and network access. Systems should generate a response within a reasonable time to realize a natural conversation. The metrics shown here are not the only automatic evaluation metrics that we use.
📕 Baselines
We provide an illustrative baseline model for this task, which is a pre-trained BART (facebook/bart-large) model fine-tuned on the ConvAI2 PERSONA-CHAT dataset with PeaCoK knowledge graph augmentation. We augment every original PERSONA-CHAT profile with maximum 5 relevant PeaCoK commonsense facts, retrieved by the ComFact knowledge linker following PeaCoK’s downstream experimental settings. Our augmented dataset and trained model are available in the baseline model repository.
Our baseline model’s performance on the test set of CPD challenge:
- word-level F1: 19.7
- cumulative 4-gram BLEU: 1.09
Note: The dataset and evaluation scripts used in our baseline model repository follow the format of ParlAI ConvAI2 challenge. However, the dataset and evaluation formats required in our CPD challenge are different from the baseline model implementations, please refer to Evaluation Data and Submission Format for submitting your models.
✍️ Submission Format and Compute Constraints
Details of the submission format are provided in the starter kit.
You will be provided conversations with 7 turns each in batches of upto 50 conversations. For each batch of conversations, the first set of turns will be provided to your model. After the response is receieved the further turns of the same conversation will be provided. Each conversation will have exactly 7 turns. Your model needs to complete all 7 responses of 50 conversations within **1 hour**. The number of batches of conversation your model will process will vary based on the challenge round.
Before running on the challenge dataset, your model will be run on the dummy data, as a sanity check. This will show up as the convai-validation phase on your submission pages. The dummy data will contain 5 conversations of 7 turns each, your model needs to complete the validation phase within **15 minutes**.
Before your model starts processing conversations, it is provided an additional time upto 5 minutes to load models or preprocess any data if needed.
GPU Track
Your model will be run on an AWS g5.2xlarge node. This node has 8 vCPUs, 32 GB RAM, and one Nvidia A10G GPU with 24 GB VRAM.
Prompt Engineering Track
Your model will be run on an AWS m5.xlarge node. This node has 4 vCPUs, 16 GB RAM*
For API usage, the following constraints will apply:
- A maximum of 2 api calls per utterance is allowed.
- Input token limit per dialog (the combined number of input tokens for 7 utterances) - 10,000
- Output token limit per dialog (the combined number of output tokens for 7 utterances) - 1,000
📅 Timeline
The challenge will take place across in 3 Rounds which differ in the evaluation dataset used for ranking the systems.
- Warm-up Round : 3rd November, 2023
- Round 1 : 8th December, 2023 (23:59 UTC)
- Round 2 : 15th January, 2024 (23:59 UTC)
- Team Freeze Deadline: 8th March, 2024 (23:59 UTC)
- Challenge End: 15th March, 2024 (23:59 UTC)
🏆 Prizes
- 🥇 First place 15,000 USD
- 🥈 Second place 7,000 USD
- 🥉 Third place 3,000 USD
Please refer to the Challenge Rules for more details about the Open Sourcing criteria for each of the leaderboards to be eligible for the associated prizes.
📖 Citing the Dataset
If you are participating in this challenge or using the dataset please consider citing the following paper:
📱 Challenge Organizing Committee
- Hiromi Wakaki (Sony)
- Antoine Bosselut (EPFL)
- Silin Gao (EPFL)
- Yuki Mitsufuji (Sony)
- Mengjie Zhao (Sony)
- Yukiko Nishimura (Sony)
- Yoshinori Maeda (Sony)
-
Keiichi Yamada (Sony)
Have queries, feedback or looking for teammates, drop a message on AIcrowd Community. Don’t forget to hop onto the Discord channel to collaborate with fellow participants & connect directly with the organisers. Share your thoughts, spark collaborations and get your queries addressed promptly.
 Continue with Google
Continue with Google
 Sign Up with Email
Sign Up with Email