
 ZW
ZW
Activity
Challenge Categories
Challenges Entered

Trick Large Language Models
Latest submissions

Small Object Detection and Classification
Latest submissions

Behavioral Representation Learning from Animal Poses.
Latest submissions
See All| graded | 176292 | ||
| graded | 174392 | ||
| failed | 174386 |

Machine Learning for detection of early onset of Alzheimers
Latest submissions
See All| graded | 144804 | ||
| graded | 144803 | ||
| graded | 144337 |


3D Seismic Image Interpretation by Machine Learning
Latest submissions

Latest submissions

5 Puzzles 21 Days. Can you solve it all?
Latest submissions

A benchmark for image-based food recognition
Latest submissions

Latest submissions
See All| graded | 143737 |

Latest submissions
See All| graded | 132876 | ||
| graded | 132875 | ||
| graded | 125932 |

Predicting smell of molecular compounds
Latest submissions

5 Puzzles, 3 Weeks | Can you solve them all?
Latest submissions
See All| graded | 116992 | ||
| graded | 116958 | ||
| graded | 116957 |

5 PROBLEMS 3 WEEKS. CAN YOU SOLVE THEM ALL?
Latest submissions

5 Problems 15 Days. Can you solve it all?
Latest submissions
See All| graded | 74276 | ||
| graded | 74272 | ||
| graded | 74255 |

5 Problems 15 Days. Can you solve it all?
Latest submissions
See All| graded | 63947 | ||
| graded | 63946 | ||
| failed | 63945 |

Detect Multi-Animal Behaviors from a large, hand-labeled dataset.
Latest submissions
See All| graded | 132876 | ||
| graded | 132875 | ||
| graded | 125932 |
| Participant | Rating |
|---|---|
 vrv
vrv
|
0 |
 ansemchaieb
ansemchaieb
|
0 |
 himanshi_gupta
himanshi_gupta
|
0 |
 devnikhilmishra
devnikhilmishra
|
0 |
| Participant | Rating |
|---|---|
 moto
moto
|
0 |
Multi Agent Behavior Challenge 2022

Checking that the goal is unsupervised representation learning
Over 4 years agoAh great, thank you for clarifying.
Checking that the goal is unsupervised representation learning
Over 4 years agoThere are some labels for demo tasks provided, so I just want to clarify my understanding. Am I correct that these are ONLY for our own evaluation use and cannot be used for any sort of training to learn the embeddings we will later submit? In other words, am I right that the goal here is to learn the representations in an unsupervised way, from only the keypoints and without using any additional labels?
This has been my approach so far but I can see how fine-tuning a model on these additional tasks might help it learn more useful representations for the hidden tasks. So if we ARE allowed to do that then it’ll be nice to know this is an option going forward 
ADDI Alzheimers Detection Challenge

Final leaderboard not visible
Almost 5 years agoNo, YOU’ve been refreshing your email all morning. I gotta say, I was trying to play it cool but when an AICrowd email popped up I clicked on that thing sooooo fast. Psych - AI Blitz 9 announcement 

Add a 4th class?
Almost 5 years agoI also tried this before seeing these, with similar results. Thinking about it more, this is kind of like reverse-boosting. We’re removing the data points that would be hardest for the model to classify - the exact opposite to what we want. We’d prefer the model see as many ‘hard’ examples as possible and spend less time on the ‘easier’ samples. With this framing it makes sense that removing these abnormal normals might not give the improvement we would wish for. Assigning to a new class, now there is an idea, although I worry it might have the same flaw.
Simulating Leaderboard shakeups to give some context
Almost 5 years agoI added some randomness to the class weights used by each ‘entry’. Interestingly, ones that do better on the public set tend to do worse on the private set and vice versa. For most splits, the difference isn’t major, but when the class balance is different between the two evaluation sets we see a divergence in the score (see both extremes of the X-axis in this graph).
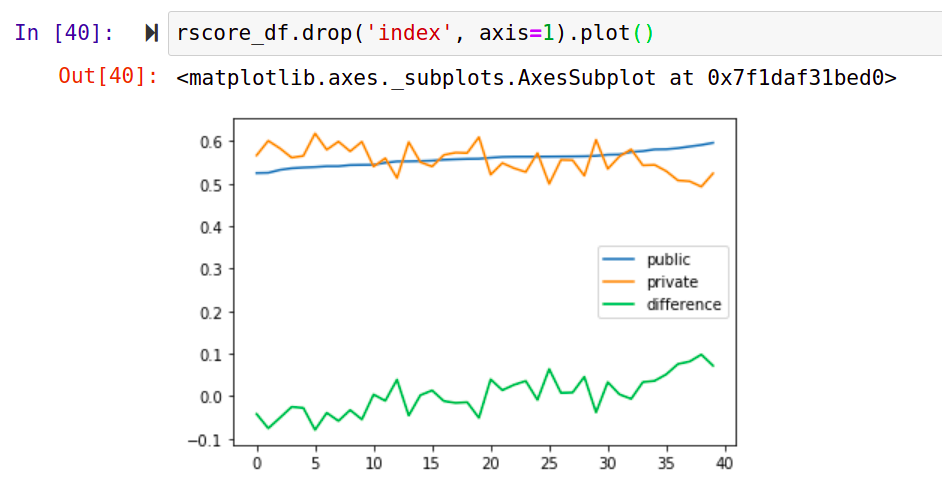
Simulating Leaderboard shakeups to give some context
Almost 5 years agoWith conversations like Do you trust your Leaderboard Score? bringing up the topic of how reliable the public leaderboard score is compared to local CV, I thought I’d add some experimental data to help us guess how large the shakeup might be.
The setup is simple. We generate a test set with the same class distribution as the validation set (I made mine 4x the size of val for 1448 records). We train a model on the rest of the data. We then score said model on ~60% of the test set and again on the remaining ~40%, storing the results. It’s the same model, so we’d expect similar scores… but with relatively small test sets we’d expect some variation. The key question: how much variation should we expect?
Running the above experiment 100 times and storing the results gives us some data to try and answer this question. For each run I record the ‘public leaderboard’ score, the ‘private leaderboard’ score and the difference between the two:
In some cases, the difference is as large as 10% - especially significant since the difference between #20 (me, as it happens) and #1 on the public leaderboard is less than 2%. Here’s the distribution of the difference as a percentage of the lower score across 100 runs:
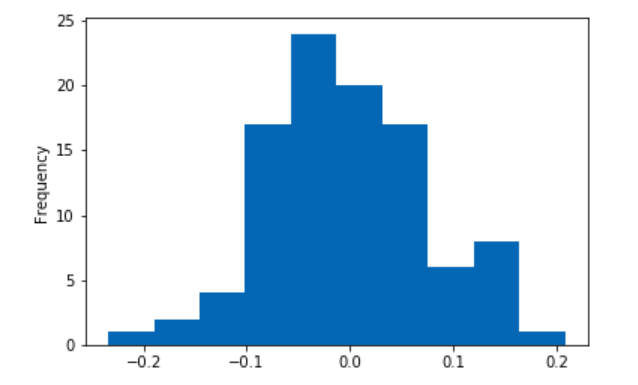
Now, I’m only training a single model for these tests - an ensemble might make fewer extreme errors and thus be less sensitive to noise. But even so, I think this experiment confirms what we’ve been thinking and points to an obvious takeaway:
The public leaderboard score gives you an idea of how well a model does based on one fairly small test set that might differ from the private test set. Better models will tend to get better scores, sure. But I think 1) Local CV is a must and 2) we can expect to see individual submissions getting fairly different scores on the private set, probably resulting in a bit of mixing on the LB. My hunch is that strong models that did well on the public set will still do well on the private set, so I’m not expecting #1 to drop to #30. BUT, those of us fighting for 0.01 to gain a few spots might be pleasantly surprised or a bit shocked in 4 days time depending on how things turn out.
A final thought: some people take randomness in an evaluation process like this to mean the competition is unfair. But everything we’re doing is based on noisy data and trying to draw conclusions despite the ever-present randomness. This is how things go. Make better models and your probability of winning will go up 
Good luck to all in the final stretch!
Motivation from the submission history
Almost 5 years ago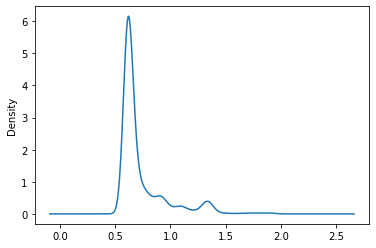
Hehe, my brain was convinced there was a separate top tier from the scatterplot but you are totally right ‘sharp spike’ was not a substantiated claim. Plotting density, it does look like a nice smooth falloff. Anyways, good luck
Motivation from the submission history
Almost 5 years agoHa, this inspired two crazy ideas. Neither worked, but at least it motivated me to try something! Hope it does the same for you
Motivation from the submission history
Almost 5 years agoI’ve been playing with the submission history. It’s interesting to me that most participants tend to hit a wall around 0.61, with only a few submissions getting beyond that and close to the top. I’d expect a more gentle falloff towards the top if we were all just making minute tweaks to a decent model/ensemble with similar features. The sharp spike makes me think maybe there is some extra innovation or edge beyond just some basic optimizations that only a few people have figured out.
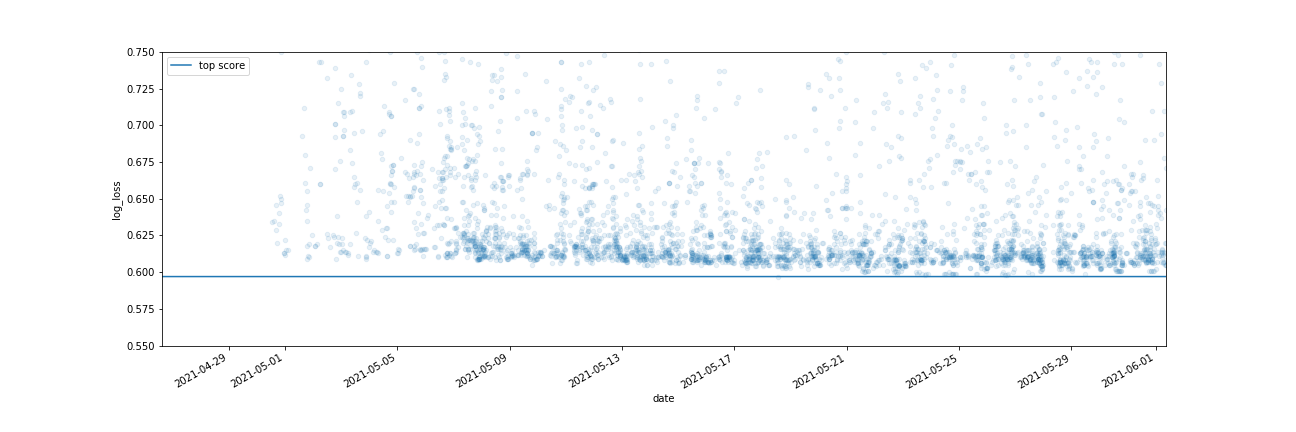
It’s maybe a bit of motivation for the final week. Can you see the breakthrough that will not just take 0.608 down to 0.607 but will leap to 0.5X? Or are we just seeing overfitting on the small test set as discussed in eg https://discourse.aicrowd.com/t/do-you-trust-your-leaderboard-score
Internal_server_error
Almost 5 years agoIt was fixed pretty quickly and I don’t think it slowed anyone down for long. Did you have other issues?
Internal_server_error
Almost 5 years agoAny chance you could NOT re-run mine? They are all re-tries of the same thing
Internal_server_error
Almost 5 years agoHi there,
not having any luck with submissions today despite starting from one that I think worked previously. I see @devnikhilmishra might have had the same issue. Could this be a server issue? (with the number of submissions I could imagine even a 200GB disk being full about now trying to store them all, for eg)
Video overview
Almost 5 years agoHi all,
I made a quick 5-minute video overview with some background, tips, visualizations and thoughts. Please check it out and let me know what you think I’m hoping this motivates one or two more people to have a go at the challenge.
YouTube link: https://youtu.be/xByX4G1gK-M

Music Demixing Challenge ISMIR 2021
Git LFS issues
Almost 5 years agoFor anyone wanting to investigate: Simply run https://www.aicrowd.com/showcase/make-your-submissions-from-inside-google-colab and note the error in the output of the first cell. I think one consequence of this is that instead of a wav file we get an LFS pointer file which the various models and such can’t decode. Pretty sure the fix is to get a data bundle or whatever it’s called for the repo that has the files and LFS enabled.
Git LFS issues
Almost 5 years agoHi there,
I was trying to get started with the challenge based on the Google Colab example notebook. Right off the bat there is a snag:
Git LFS: (0 of 5 files) 0 B / 5.89 MB
batch response: This repository is over its data quota. Account responsible for LFS bandwidth should purchase more data packs to restore access.
error: failed to fetch some objects from 'https://github.com/AIcrowd/music-demixing-challenge-starter-kit.git/info/lfs'
This overflows into some other issues - I had trouble running any of the code that was supposed to access the test file (“data/test/Mu - Too Bright/mixture.wav”) unless I ran the data download step. And I’m not sure if it is related but at the end of the notebook trying to submit I see git LFS skipping files and an error including remote: fatal: pack exceeds maximum allowed size
Is this a problem I’m causing or could it be (as the first error suggests) an issue with the repository data quota?
Notebooks
-
 Dealing with Class Imbalance Looking at different ways to address class imbalance in this datasetJohnowhitaker· About 5 years ago
Dealing with Class Imbalance Looking at different ways to address class imbalance in this datasetJohnowhitaker· About 5 years ago -
 FastAI Tabular Starter Minimal submission making predictions using fastai's tabular learnerJohnowhitaker· About 5 years ago
FastAI Tabular Starter Minimal submission making predictions using fastai's tabular learnerJohnowhitaker· About 5 years ago
Rambling video of my process so far
About 4 years agoTrying something different under the goal of ‘working in public’, I’ve made a sort of video diary of the first few hours on this challenge that lead to my current entry. It’s up on YouTube: Come along for the ride as I dive into an ML contest (MABe 2 on AICROWD) - YouTube (Skip to 18:00 where I decide to focus on this challenge).
To summarise the approach:
Using a latent dimension of 40 for the perceiver, training very briefly and using just the reduced latent array as the representation submitted: 18/0.128. Using JUST the hand-crafted features: 18/0.135. Combining both with a few extra sprinkles: 13/0.173.
I can see that the trick with this contest is going to be packing that 100-dim representation with as many useful values as possible. What ideas do you have? Any other interesting SSL approaches? And has anyone had luck using the demo tasks to create useful embeddings? Let’s brainstorm