
 ID
ID
Activity
Challenge Categories
Challenges Entered

Build an LLM agent for five real-world games
Latest submissions


Create Context-Aware, Dynamic, and Immersive In-Game Dialogue
Latest submissions

Automating Building Data Classification
Latest submissions
See All| graded | 280898 | ||
| graded | 280897 | ||
| graded | 280888 |
Generate Synchronised & Contextually Accurate Videos
Latest submissions


Understand semantic segmentation and monocular depth estimation from downward-facing drone images
Latest submissions

Audio Source Separation using AI
Latest submissions

A benchmark for image-based food recognition
Latest submissions

Using AI For Building’s Energy Management
Latest submissions

What data should you label to get the most value for your money?
Latest submissions
See All| graded | 179064 | ||
| graded | 179053 | ||
| graded | 179052 |


ASCII-rendered single-player dungeon crawl game
Latest submissions

Machine Learning for detection of early onset of Alzheimers
Latest submissions
See All| graded | 140851 |

3D Seismic Image Interpretation by Machine Learning
Latest submissions
See All| graded | 157061 | ||
| graded | 156573 | ||
| graded | 156572 |

Latest submissions

Play in a realistic insurance market, compete for profit!
Latest submissions
See All| graded | 110896 | ||
| graded | 110895 | ||
| graded | 110894 |

5 Puzzles 21 Days. Can you solve it all?
Latest submissions

5 Puzzles 21 Days. Can you solve it all?
Latest submissions

Latest submissions

5 Puzzles, 3 Weeks. Can you solve them all? 😉
Latest submissions

Predicting smell of molecular compounds
Latest submissions

Find all the aircraft!
Latest submissions

5 PROBLEMS 3 WEEKS. CAN YOU SOLVE THEM ALL?
Latest submissions
See All| graded | 157061 | ||
| graded | 156573 | ||
| graded | 156572 |
| Participant | Rating |
|---|---|
 saeful_ghofar_zamianie_putra
saeful_ghofar_zamianie_putra
|
0 |
 shivam
shivam
|
136 |
 vrv
vrv
|
0 |
| Participant | Rating |
|---|---|
|
shivam
|
136 |
Brick by Brick 2024-bc2191

The Web Conf Announcement
Over 1 year agoHi Sneha, How many presenters are covered by the travel grant? Does each registration apply to only one presenter?
Challenge Announcement
Over 1 year agoHi Sneha, we have already granted repo access to all the emails, but we recently received an email stating that the invitation was declined. Is this okay?
‼️ ✍️ Important: Submission Documentation Guidelines
Over 1 year agoI agree with Kaushik. Each contestant’s pipeline is still evolving up to the deadline. The documentation submission needs to be set a few days after the leaderboard locks for better assurance.
Data Purchasing Challenge 2022
I need to say this
About 4 years agoWow. What a clickbait-y title. But that got your attention 
I haven’t properly said it before, but Thank you Zew and Aicrowd for organizing this competition. Thank you, fellow participants. I learn lots of new stuff from this, especially from the top LB solutions & other participants’ notebooks. I think I already got in my mind the best practice when facing this kind of problem in my work in the near future (sooner or later I think I’ll be facing this too, and labeling will be more expensive because of engineer/scientist level labeler needed for the data).
Hope you guys are always in good health.
Cheers
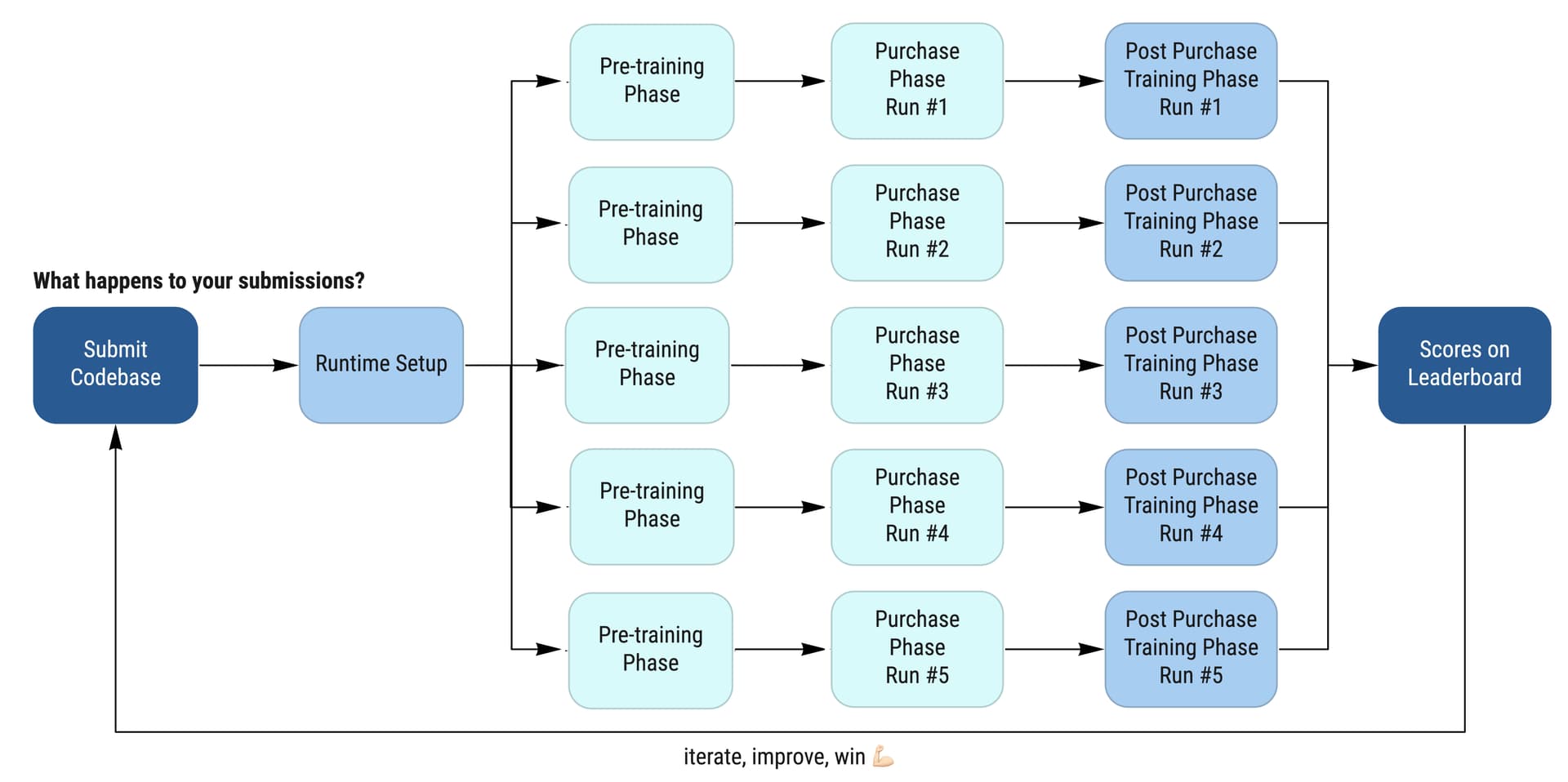
:rotating_light: Select submissions for final evaluation
About 4 years agoHi @dipam , just need a little clarifications about your post :
The detailed steps are given below:
- Eligible teams will select two of their submissions to evaluate - Eligibility criteria to be announced soon, it will be based on Round 2 leaderboard.
- Each submission will run through the pre-train and the purchase phase on the end of competition dataset.
- The same purchased labels will be put through 5 training pipelines - Details to be released soon.
- Each training pipeline will be run for 2 seeds and scores averaged, to address any stochasticity in scores.
- To avoid issues due to difference of average scores from different training pipelines, a Borda ranking system will be used.
while the 5 training pipelines results scored using Borda ranking system, how about the submissions? is it the highest score from the submission that is being used or is it an average from both submission results?
Simple Way to know any defect on image, finding noisy label, etc using OpenCV
About 4 years agoHi guys, I made a notebook about a simple method to detect defects on images using OpenCV.
It really helps me in detecting noisy labels and adding extra strategies on selecting which data to buy/skip.
you can read it here: AIcrowd | Simple Way to Detect Noisy Label with opencv | Posts
Hope it helps with your training or buying strategy too!
Also pls leave some likes if you don’t mind!
📹 Town Hall Recording & Resources from top participants
About 4 years agoI tried this locally too! 
but still beaten by buying naive prediction on dent label
Need Clarification for Round 2
About 4 years agoHi AIcrowd Team, just want to clarify something :
- In the post-purchase training phase,
# Create a runtime instance of the purchased dataset with the right labels purchased_dataset = instantiate_purchased_dataset(unlabelled_dataset, purchased_labels) aggregated_dataset = torch.utils.data.ConcatDataset( [training_dataset, purchased_dataset] ) print("Training Dataset Size : ", len(training_dataset)) print("Purchased Dataset Size : ", len(purchased_dataset)) print("Aggregataed Dataset Size : ", len(aggregated_dataset)) DEBUG_MODE = os.getenv("AICROWD_DEBUG_MODE", False) if DEBUG_MODE: TRAINER_CLASS = ZEWDPCDebugTrainer else: TRAINER_CLASS = ZEWDPCTrainer trainer = ZEWDPCTrainer(num_classes=6, use_pretrained=True) trainer.train( training_dataset, num_epochs=10, validation_percentage=0.1, batch_size=5 ) y_pred = trainer.predict(val_dataset) y_true = val_dataset_gt._get_all_labels()
shouldn’t it be something like this?
trainer.train( aggregated_dataset , num_epochs=10, validation_percentage=0.1, batch_size=5 )
- Because the combined and different time budget, shouldn’t it be something like this?
instead of the original diagram?
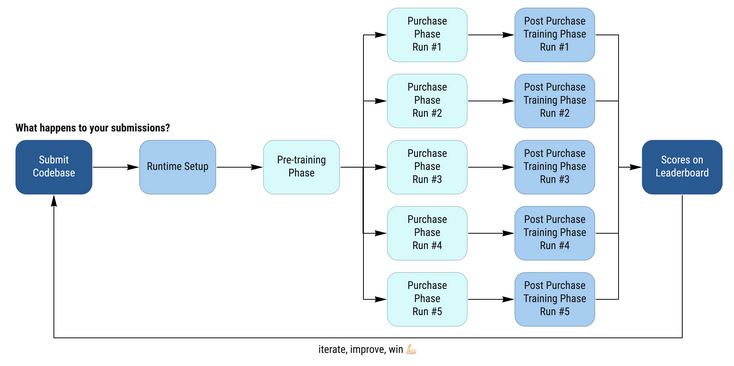
or did I assume it wrong?
Thanks.
Brainstorming On Augmentations
About 4 years ago-
I just want to make it more versatile to any augmentation pipeline I want to use. or maybe that’s the incorrect way? Does anyone else mess with the dataset classes only me? (asking the others)
-
I deleted it to show the result “my way” of training the random pick one from scratch.
My main pipeline is consist of pretraining, using the model to select purchases, resetting the weight then train it from scratch. I don’t think pretraining won’t do anything helpful if I want to do that. -
I think reproducing is supposed to be doing the same and using the same thing. so probably just like you guess or the maybe seed. thanks for the indirect suggestion I’ll try to add every method from here Reproducibility — PyTorch 1.10 documentation
-
sorry for that I guess?
hi @shivam , sorry to drag you in, just to make sure are there any specific rules about only using a certain way in making the solution (like class, code writing, ml pipelines, frameworks, save path, etc)?
Brainstorming On Augmentations
About 4 years agoYep.
At first, I tried feeding both the raw + pre-processed ones but it gives a really bad score.
probably because different way of convnet learns from those two types of images.
now I go either using the pre-processed only or raw only.
the seismic challenge while back, the rms attribute does help scale the amplitude. while the raw doesn’t really help me. Apparently, it’s quite different now while the raw can perform well too, the pre-trained weight also helps significantly.
Brainstorming On Augmentations
About 4 years agoI’m only using :
- RandomHorizontalFlip,
- RandomVerticalFlip,
- RandomRotation,
you can see it on my notebook here :
I don’t use any color augmentation at all because some of my current high submissions came from using no raw image input (though I still run some experiments on raw input one in case the preprocess one hit the ceiling, the same experience from the seismic competition before with @santiactis )
Experiments with “unlabelled” data
About 4 years agoyes, it’s very significant.
From my experiment notebook its something like this :
| exp no. | augmentation | pretrained | purchase_method | score_pretraining_phase | score_purchase_phase | score_validation_phase | LB_Score |
|---|---|---|---|---|---|---|---|
| 1 | NO | NO | NO | 0.773 | 0.773 | 0.760 | |
| 2 | NO | NO | RANDOM 3000 | 0.773 | 0.804 | 0.760 | |
| 3 | NO | NO | ALL 10000 | 0.773 | 0.841 | 0.835 | |
| 4 | NO | YES | NO | 0.857 | 0.857 | 0.850 | |
| 5 | NO | YES | RANDOM 3000 | 0.857 | 0.864 | 0.845 | 0.851 |
| 6 | NO | YES | ALL 10000 | 0.857 | 0.892 | 0.875 | |
| 7 | YES | YES | NO | 0.868 | 0.868 | 0.865 | |
| 8 | YES | YES | RANDOM 3000 | 0.868 | 0.886 | 0.869 | 0.880 |
| 9 | YES | YES | ALL 10000 | 0.868 | 0.902 | 0.893 |
the notebook :
My Multiple Experiments Results ( the random one got 0.88 on LB)
About 4 years agoHere’s my multiple experiment results score that I log into tables.
I’m using this same parameter for each experiment :
model : efficienet-b1
input: raw image
epoch: 20
optim: Adam
tl;dr, use augmentation and pre-trained weight.
I hope you it help you guys, especially for those who just joined.
Size of Datasets
About 4 years agowhat’s your comment about this @shivam ?
I think it’s 5000 training images, 3000 to purchase, 3000 to test right? just as in the overview.
Full list of available pretrained weights
About 4 years agowow, which pytorch version that got vit? nightly version?
Submit failed with no error log
About 4 years agoyes, it should be like that but mine didn’t show up.
What is this validation submission phase error log means?
Over 4 years ago==================================
Deleting unsupported pre-trained model: ./.cache/pip/wheels/76/ee/9c/36bfe3e079df99acf5ae57f4e3464ff2771b34447d6d2f2148/gym-0.21.0-py3-none-any.whl
Deleting unsupported pre-trained model: ./.cache/pip/http/1/3/0/c/a/130ca645ced2b235e6f69505044bb4923f610dbb4bc6c8e1d76a50bb
Deleting unsupported pre-trained model: ./.cache/pip/http/8/f/8/e/b/8f8eb31d64d7424ab679aad519c22a7bf4f40ab17d1c4bad52b49a9c
Deleting unsupported pre-trained model: ./.cache/pip/http/a/d/c/0/3/adc03ed04ad13ffdeee3c838911d25a9f3659c9e3590f34fa6bf3a7e
Deleting unsupported pre-trained model: ./.git/objects/pack/pack-c148ae0f71d82068775278a3044e1a3c25b5f4a3.pack
Time left: 10800
timeout: the monitored command dumped core
/home/aicrowd/run.sh: line 38: 61 Segmentation fault timeout -s 9 $AICROWD_TIMEOUT_INFO python aicrowd_client/launcher.py
Submit failed with no error log
Over 4 years agoI got error in the “Validate Submission” phase but with no log too
🚀 Discussion on Starter Kit
Over 4 years agohi @vrv ,
I tried using this submission method instead : AIcrowd
the push works, checked it on gitlab, but somehow it’s not on the submission. the tag `submission-`` prefix is right too. Any idea why?
Notebooks
-
 [Task 3 - Score 0.836] 3 Common Models Trained Separately Just 3 Common Model Trained Separatelyleocd· Almost 4 years ago
[Task 3 - Score 0.836] 3 Common Models Trained Separately Just 3 Common Model Trained Separatelyleocd· Almost 4 years ago -
 Simple Way to Detect Noisy Label with opencv using opencv to enhance your strategy on training and buyingleocd· About 4 years ago
Simple Way to Detect Noisy Label with opencv using opencv to enhance your strategy on training and buyingleocd· About 4 years ago -

-
 [LB 0.880] My Experiment Results + Baseline too I guess 😬 Experiment Resultsleocd· About 4 years ago
[LB 0.880] My Experiment Results + Baseline too I guess 😬 Experiment Resultsleocd· About 4 years ago -
 Exploration, Body Paint Color Dominance, Image Transforms Data Exploration, Extracting Body Paint by Color Dominance from image, and Image Transformationleocd· Over 4 years ago
Exploration, Body Paint Color Dominance, Image Transforms Data Exploration, Extracting Body Paint by Color Dominance from image, and Image Transformationleocd· Over 4 years ago -
 [Explainer] Introduction and General Approach Final Pack! Introduction to this challenge, general approach, my approach, and what I learn from the othersleocd· Over 5 years ago
[Explainer] Introduction and General Approach Final Pack! Introduction to this challenge, general approach, my approach, and what I learn from the othersleocd· Over 5 years ago -
 [Explainer] Need extra features? Different input approach? Try Seismic Attributes! Basically it’s a math “Instagram-Snapchat-like” filter for seismic data. There are a lot of Seismic Attributes available.leocd· Over 5 years ago
[Explainer] Need extra features? Different input approach? Try Seismic Attributes! Basically it’s a math “Instagram-Snapchat-like” filter for seismic data. There are a lot of Seismic Attributes available.leocd· Over 5 years ago
Tentative Winner Announcement
Over 1 year agoThanks, @snehananavati ! When is the final official announcement expected?
Will the current rankings/groups remain the same and only validation phase left to make sure the submission valid?
imho this would help the finalists gain confidence in registering and arranging for the conference.