
 Ranchi, IN
Ranchi, IN
Activity
Challenge Categories
Challenges Entered



Measure sample efficiency and generalization in reinforcement learning using procedurally generated environments
Latest submissions

3D Seismic Image Interpretation by Machine Learning
Latest submissions

5 Puzzles 21 Days. Can you solve it all?
Latest submissions

A benchmark for image-based food recognition
Latest submissions

Predicting smell of molecular compounds
Latest submissions
See All| graded | 87976 | ||
| graded | 87972 | ||
| graded | 87968 |

Classify images of snake species from around the world
Latest submissions

5 Problems 21 Days. Can you solve it all?
Latest submissions
See All| graded | 124438 | ||
| graded | 124411 | ||
| graded | 124409 |

5 Puzzles, 3 Weeks | Can you solve them all?
Latest submissions

5 PROBLEMS 3 WEEKS. CAN YOU SOLVE THEM ALL?
Latest submissions
See All| graded | 87976 | ||
| graded | 87972 | ||
| graded | 87968 |

Grouping/Sorting players into their respective teams
Latest submissions

5 Problems 15 Days. Can you solve it all?
Latest submissions

5 Problems 15 Days. Can you solve it all?
Latest submissions
See All| graded | 66513 | ||
| graded | 66379 | ||
| graded | 66233 |
Immitation Learning for Autonomous Driving
Latest submissions

5 PROBLEMS 3 WEEKS. CAN YOU SOLVE THEM ALL?
Latest submissions
See All| graded | 82361 | ||
| graded | 82360 | ||
| graded | 82359 |

Latest submissions

Words are more powerful than actions!
Latest submissions
| Participant | Rating |
|---|---|
 bhuvanesh_sridharan
bhuvanesh_sridharan
|
0 |
 ruhi_parveen
ruhi_parveen
|
0 |
| Participant | Rating |
|---|---|
 akshatcx
akshatcx
|
-39 |
|
bhuvanesh_sridharan
|
0 |
-
BayesianMechanics AIcrowd Blitz - May 2020View
-
BayesianMechanics AIcrowd Blitz⚡#2View
-
BayesianMechanics AI for Good - AI Blitz #3View
-
BayesianMechanics AI Blitz #4View
-
BayesianMechanics AI Blitz #6View
Learn-to-Race: Autonomous Racing Virtual Challenge

Requesting Sensor Information
Over 4 years agoSomehow, all the sensor configs that were a part of the initial setup of Arrival in the Thruxton racetrack are now gone (most probably because I tried to switch over to Anglesey). Can I please get the exact angles and configuration values that people get for their CameraFrontRGB, SegmFrontRGB, etc. It was working for me until now, and I can easily add new sensors, so just the info works, but the JSON or YAML files that I can directly feed in will help a little more.
Need Help with the Simulator documentation
Over 4 years agoThank you, thank you sooo much! That was the issue, I have spent so much time trying to debug it, I saw those lines but thought they were okay then. It works now, thanks a lot.
Need Help with the Simulator documentation
Over 4 years agoThis picture tells it call, I changed the cameras config, I added the right sensors, I am getting 4 images, but WHY ARE THEY ALL THE SAME??? Where is my BirdsEye and Segmentation map? Are my settings as RGB8 and FOV 90 wrong? Are there more things I missed changing?
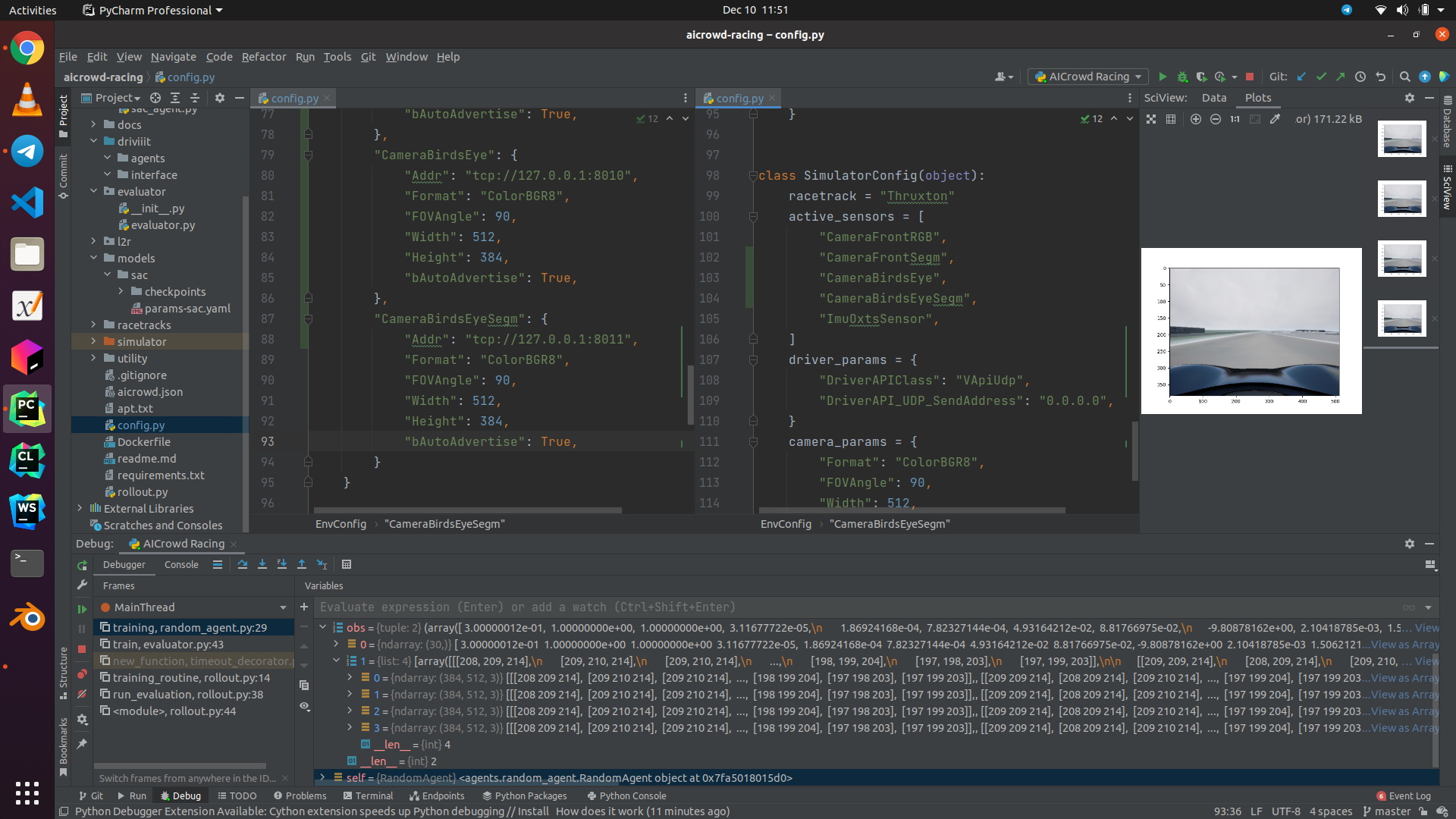
Need Help with the Simulator documentation
Over 4 years agoI tried a lot to get the segmentation map, it doesn’t work. There is a very clear type mismatch in RacingEnv.__init__ in the following lines, where self.cameras should have 3-tuples.
if birdseye_if_kwargs:
self.cameras.append(("CameraBirdsEye", utils.CameraInterface(**birdseye_if_kwargs)))
And the same with all others of the similar form. This cannot be ignored because later in the pipeline you do unpack this tuple as follows in the the multimodal setter.
for name, params, cam in self.cameras:
_shape = (params["Width"], params["Height"], 3)
_spaces[name] = Box(low=0, high=255, shape=_shape, dtype=np.uint8)
And unlike the self.cameras dict in the config, I don’t know what to set here. Some help please.
Need Help with the Simulator documentation
Over 4 years agoOkay, so I got one part of it, the 30 length vector is described in the variables at top of the env.py file in the comments with the array. I am still confused as to what to pass to constructor of env to get the segmentation maps, and what are these something_if_kwargs variables that seem to be everywhere.
Need Help with the Simulator documentation
Over 4 years agoNow that everything is setup and working, I am having a hard time figuring out how to customize my inputs and change the config on the simulator, and the AICrowd wrappers and their documentation are a little confusing.
Things I cannot really find easily documented (trying to find it, but clarification would help):
- Why is the pose a 30 length vector? Why is it not just pitch, roll and yaw, and the 3 vector for the translation, giving the me 6 DOF representation of the 12 element pose transform matrix. I am talking about the pose as returned by the
env.step()function? - The config file seems to suggest that I can access segmentation maps, and an overhead view, atleast during training. But the AICrowd wrapper’s
env.step()only gives me access to the 30-length pose vector, not the other stuff that seems useful. How do I get access to that?env.make()exists, which is called by the AICrowd evaluator class, should I just bypass the evaluator and instantiate my own simulator for training?
Small Error in documentation:
-
env.step()claims to return pose and image as a dict in the docstring, it even talks about the keys, even though it returns as a tuple as clearly mentioned in the docstring forenv._observe().
Problems obtaining the Learn2Race simulator
Over 4 years agoYeah, the download started for me. It’s a little slow, claims to take 14 hours for a 3GB file while 500MB videos are taking like 20 mins, so it’s most likely server speed limits. But it works.
Problems obtaining the Learn2Race simulator
Over 4 years agoI am unable to obtain the simulator, I have filled out the Google form and also uploaded the document with my name and email on the AICrowd website a day back. I haven’t gotten a mail yet, but when I go to resources, I see the button which leads me to this link and then dies: http://g.jonfranc.com:81/. What can I do to obtain the simulator / how long would I need to wait for an email?
Tile-Slider
AI Blitz #6
Issues with the Training Data
About 5 years ago
This is the details for the same image. Both are in the training dataset for problem Chess-Win-Prediction.
We have input the same position on LiChess engine and we get this:
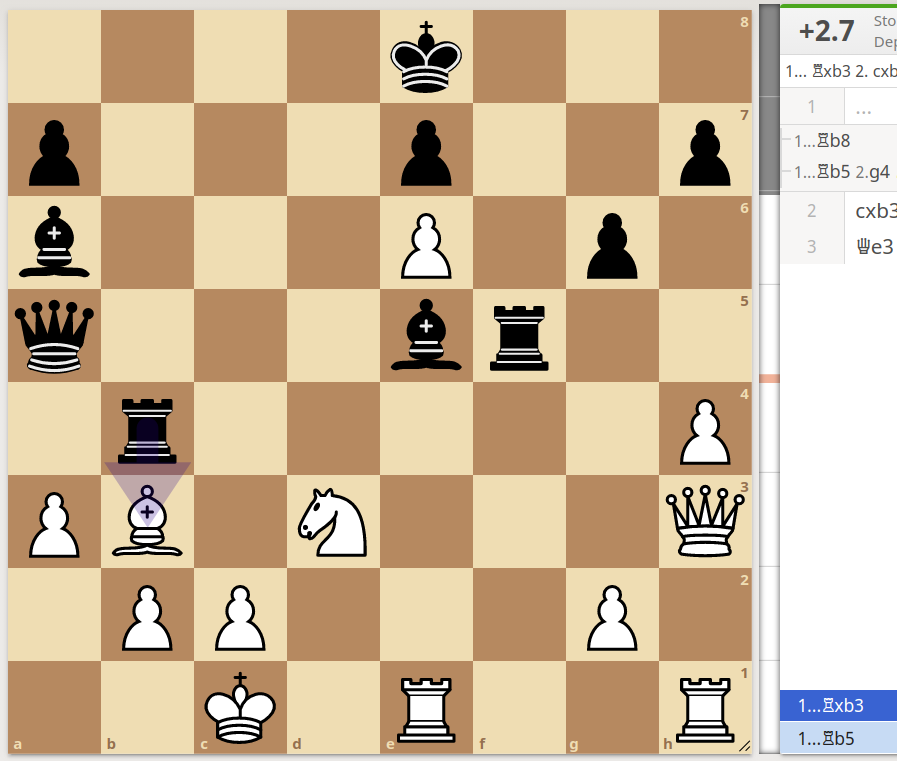
I hope that both the images are identical, the move is correctly assigned to black. But any engine seems to suggest that White will win this, Stockfish is giving it a +2.7 evaluations (very winning) in favor of white. Nevertheless, the official solution sees to predict that black wins. There is no possible castling or en-passant rule that can make that happen.
Am I missing something or is there an issue with the training data?
Link of the Stockfish evaluation: https://lichess.org/analysis/4k3/p3p2p/b3P1p1/q3br2/1r5P/PB1N3Q/1PP3P1/2K1R2R_b_-_-_0_1
We seem to be having this issue with a lot of other images.
What is both sides have the same number of pieces
Over 5 years agoTo the best of my counting ability, this image has an equal number of pieces of both colors.
8 Pawns, 3 Minor Pieces, 2 Rooks, a Queen and a King on both sides.

This is image 1539 in the test dataset for problem 1.
What should be the answer in such a case?
Problem: AIBlitz Chess - 1. Chess Pieces
Food Recognition Challenge
🚀 Round 3 is live with more images and classes!
Over 5 years agoSeems like the data files are named .tar.gz but they are .zip files. Please rename.
AI for Good - AI Blitz #3
Explained by the Community | 100 CHF Prize contest 🎉
Over 5 years agoI thought I shared the friend link, so that should not be a problem, but here it is again: https://medium.com/bayesian-mechanics/deep-learning-contests-steering-angle-predictions-636edb40d142?source=friends_link&sk=299f5d330fe195f85e7ffc3f99ab5915
Please let me know if you can access it and if there are issues we can always shift it wherever convienient.
In addition, I am not a part of the Meduim partner program, the blog is not monetized, so it should not be in the paywall even when directly searched from google.
Explained by the Community | 100 CHF Prize contest 🎉
Over 5 years agoHello, I am Animesh Sinha from team Bayesian Mechanics, and here is a solution baseline for the AUTODRI problem in this contest.
Please share thoughts and comments.
Can we use pre-trained pytorch models?
Over 5 years agoWhat if the pretrained models are not a part of either library, but trained on a standard publically available dataset, eg. ImageNet. And similarly many of the transformer models, BERT, GPT2, etc.
And who decides what a popular dataset is.
Change in Dataset Links
Over 5 years agoAre the packages damaged, I cannot unzip the files using the new links.
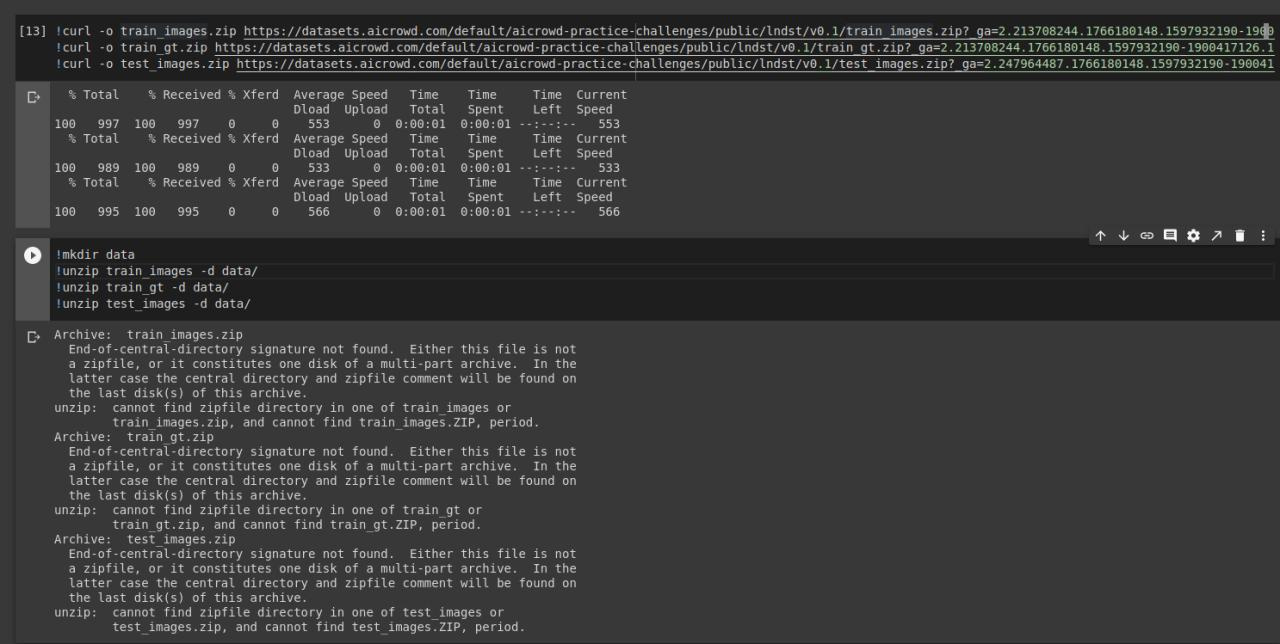
FNEWS
But what about the data leak?
Over 5 years agoI hope you will consider that many teams did not exploit the data leak and spent a lot of time trying out different models, and the implementation that gets a 99.9% is certainly not a leak. I hope you will add additional data and check, since even the Kaggle precedent dictates that if a data leak is found the question stands and the teams which found it do get an unfair advantage. But testing with more data seems to be the best. Slashing off the question seems highly unfair.
Requesting Sensor Information
Over 4 years agoOops, never mind, figured it out, the config file was in the arrival simulator and the guide on how to reload from the YAML file was here: https://learn-to-race.readthedocs.io/en/latest/sensors.html