
 IN
IN
Activity
Challenge Categories
Challenges Entered


Build an LLM agent for five real-world games
Latest submissions
See All| graded | 308684 | ||
| failed | 308682 | ||
| graded | 306148 |


Create Context-Aware, Dynamic, and Immersive In-Game Dialogue
Latest submissions
See All| failed | 285403 | ||
| failed | 285312 | ||
| failed | 283221 |

Improve RAG with Real-World Benchmarks | KDD Cup 2025
Latest submissions
See All| failed | 292367 | ||
| failed | 292325 | ||
| graded | 286048 |

A benchmark for image-based food recognition
Latest submissions
See All| failed | 172430 | ||
| graded | 172229 | ||
| failed | 172228 |

Using AI For Building’s Energy Management
Latest submissions
See All| failed | 193327 | ||
| failed | 193315 | ||
| failed | 193310 |

What data should you label to get the most value for your money?
Latest submissions
See All| failed | 178246 | ||
| failed | 177490 | ||
| failed | 177425 |


Behavioral Representation Learning from Animal Poses.
Latest submissions

Airborne Object Tracking Challenge
Latest submissions

ASCII-rendered single-player dungeon crawl game
Latest submissions
See All| graded | 155140 | ||
| graded | 147319 |

Latest submissions

Machine Learning for detection of early onset of Alzheimers
Latest submissions

5 Puzzles 21 Days. Can you solve it all?
Latest submissions

Sample Efficient Reinforcement Learning in Minecraft
Latest submissions

The first, open autonomous racing challenge.
Latest submissions
See All| graded | 176785 | ||
| graded | 176487 | ||
| graded | 176466 |

Measure sample efficiency and generalization in reinforcement learning using procedurally generated environments
Latest submissions
See All| submitted | 90059 | ||
| graded | 83575 | ||
| failed | 81249 |

5 Puzzles 21 Days. Can you solve it all?
Latest submissions

Self-driving RL on DeepRacer cars - From simulation to real world
Latest submissions

Robustness and teamwork in a massively multiagent environment
Latest submissions


5 Puzzles 21 Days. Can you solve it all?
Latest submissions

Latest submissions

Play in a realistic insurance market, compete for profit!
Latest submissions
See All| graded | 125874 | ||
| graded | 121934 | ||
| failed | 116909 |

5 Puzzles 21 Days. Can you solve it all?
Latest submissions

Multi-Agent Reinforcement Learning on Trains
Latest submissions

A dataset and open-ended challenge for music recommendation research
Latest submissions
See All| failed | 303444 |

A benchmark for image-based food recognition
Latest submissions
See All| graded | 114994 | ||
| graded | 114972 | ||
| failed | 114971 |

Latest submissions

Sample-efficient reinforcement learning in Minecraft
Latest submissions

Latest submissions
See All| failed | 124981 | ||
| failed | 124727 | ||
| failed | 124726 |

5 Puzzles, 3 Weeks. Can you solve them all? 😉
Latest submissions

Multi-agent RL in game environment. Train your Derklings, creatures with a neural network brain, to fight for you!
Latest submissions

Predicting smell of molecular compounds
Latest submissions

Classify images of snake species from around the world
Latest submissions

Find all the aircraft!
Latest submissions

5 Problems 21 Days. Can you solve it all?
Latest submissions

5 Puzzles 21 Days. Can you solve it all?
Latest submissions

5 Puzzles, 3 Weeks | Can you solve them all?
Latest submissions

5 PROBLEMS 3 WEEKS. CAN YOU SOLVE THEM ALL?
Latest submissions

Grouping/Sorting players into their respective teams
Latest submissions

Latest submissions


Sample-efficient reinforcement learning in Minecraft
Latest submissions

Multi Agent Reinforcement Learning on Trains.
Latest submissions
Latest submissions
See All| graded | 191633 | ||
| submitted | 191628 | ||
| submitted | 191622 |

Latest submissions
See All| graded | 60315 | ||
| graded | 60314 |

Latest submissions

5 Problems 15 Days. Can you solve it all?
Latest submissions

Project 2: Road extraction from satellite images
Latest submissions

Project 2: build our own text classifier system, and test its performance.
Latest submissions

Predict if users will skip or listen to the music they're streamed
Latest submissions

Identifying relevant concepts in a large corpus of medical images
Latest submissions
Latest submissions


Latest submissions
See All| graded | 67702 | ||
| graded | 67701 | ||
| graded | 67600 |
Latest submissions

Predict if users will skip or listen to the music they're streamed
Latest submissions

Latest submissions

Latest submissions

Predicting wine quality
Latest submissions

Predict whether an individual will be back to prison
Latest submissions

Latest submissions

Analyse Sentiment From Sound Clips
Latest submissions


Reinforcement Learning, IIT-M, assignment 1
Latest submissions

5 puzzles and 1 week to solve them!
Latest submissions

Latest submissions

Multi-Agent Reinforcement Learning on Trains
Latest submissions

Latest submissions

Localization, SLAM, Place Recognition, Visual Navigation, Loop Closure Detection
Latest submissions

Identify Words from silent video inputs.
Latest submissions

A Challenge on Continual Learning using Real-World Imagery
Latest submissions

Use an RL agent to build a structure with natural language inputs
Latest submissions
Latest submissions
See All| graded | 281041 | ||
| failed | 281038 | ||
| graded | 281037 |

Generating answers using image-linked data
Latest submissions
See All| failed | 292367 | ||
| failed | 292325 | ||
| graded | 286048 |

Synthesising answers from image and web sources
Latest submissions
See All| graded | 283744 | ||
| graded | 282957 | ||
| graded | 282706 |

Contextual answering in multi-turn dialogue
Latest submissions
See All| graded | 282958 | ||
| graded | 282199 | ||
| failed | 282198 |
| Participant | Rating |
|---|---|
 BhaviD
BhaviD
|
0 |
 will_kwan
will_kwan
|
0 |
 lars12llt
lars12llt
|
0 |
 jansi_rani_s_v
jansi_rani_s_v
|
0 |
|
|
0 |
 saketha_ramanujam
saketha_ramanujam
|
0 |
 vrv
vrv
|
0 |
 jerome_patel
jerome_patel
|
0 |
 shivam
shivam
|
136 |
|
|
0 |
 krishna_kaushik
krishna_kaushik
|
0 |
 unnikrishnan.r
unnikrishnan.r
|
261 |
|
|
0 |
| Participant | Rating |
|---|---|
|
vrv
|
0 |
 aicrowd-bot
aicrowd-bot
|
|
|
shivam
|
136 |
|
unnikrishnan.r
|
261 |
Orak Game Agent Challenge 2025 Forum

Supemario, game screenshot works?
5 months agoHello @RickySong @ChoiSoojin,
On the evaluation server, we run the games using the same scripts as the ones in the starter kit. To keep the behavior consistent, we updated the starter kit to run in headless mode as well.
If you’d like to enable visualizations again, you can switch the environment creation line in super_mario_env.py (around line 217):
to:
self.env = gym_super_mario_bros.make(
'SuperMarioBros-1-1-v1',
render_mode='human',
apply_api_compatibility=True
)
Session cannot get data including mcp_urls
5 months agoHello @ns601023
It seems like you are using an older version of the starter kit. Can you please pull the new changes and try again?
git pull origin master --rebase
Pokemon map is broken?
5 months ago@ilya_gusev is there a particular submission you are referring to that I can check?
We didn’t change anything specific to pokemon and wouldn’t expect this change. Maybe the game hasn’t started yet? The game ROM we received from Krafton team starts at the menu screen and the “Map on Screen” wouldn’t be defined for that screen.
Is there something I can cross check on the server logs or can you give the exact steps to replicate this issue so that we can pass this to Krafton team?
Model submission
5 months agoWhile running remote mode, it seems like the Star Craft failed after entering the second episode, is it possible that there’s a problem with the code in the MCP server or game envs of AIcrowd?
The issue was due to requests getting queued and dequeued arbitrarily at MCP server. We moved to a gRPC based implementation to get around this issue.
Please pull the recent changes made to starter kit and let us know if you still run into any issues.
long will the evaluation process usually take?
It’s subjective. However, if you use the random agents (not really random, they simply repeat the same static action), this is what you should expect.
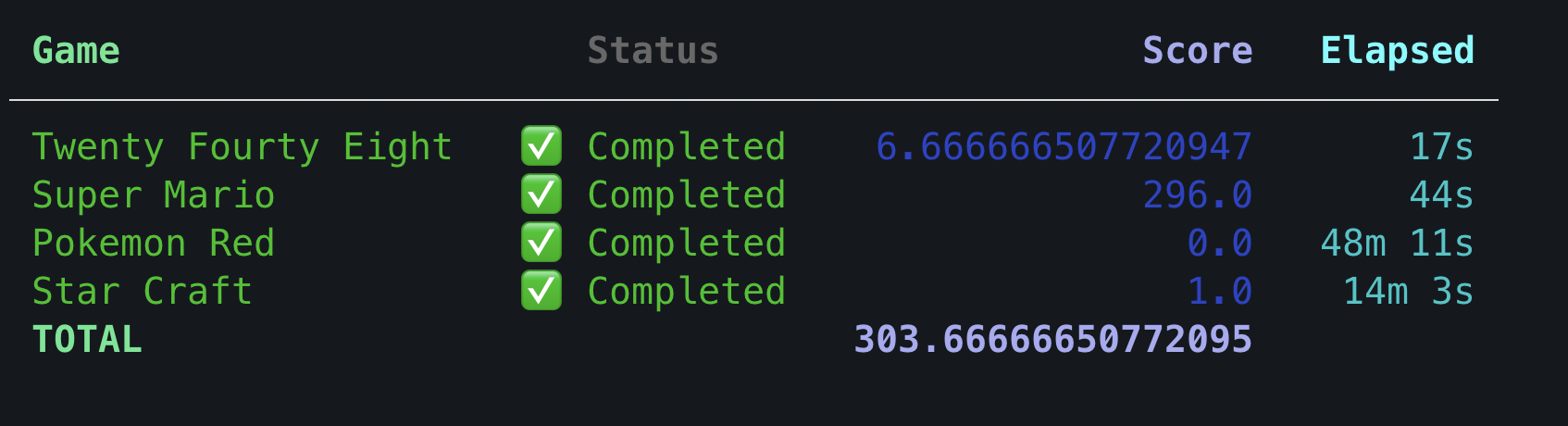
Do score only appear after all games are completed?
Yes. Your submission must complete all games to be marked as graded. Your submission won’t appear on leaderboard otherwise.
will it directly show the score on the submission page once all games are completed or it will take some additional time to make the score shown on the submission page
Your submission would be marked as failed if it doesn’t complete all the games. In case your evaluation times out i.e. doesn’t finish all the games in 12 hours, the submission would eventually get marked as failed.
Clarification on ORAK Scoring Standards and Remote Mode Episode Settings
5 months agoWhen running the games in remote mode, how many episodes are executed for each game?
Three episodes each for all games.
And for games like 2048, is the final score taken as the average of three rounds
Final score for each game would be the average scores across episodes.
Super_mario
5 months agoHey, we released a few patches to the starter kit that would remove fastmcp dependencies. Can you please pull the recent changes, give it a try and reach out to us if you are still running into problems?
📢 Starter Kit Update
5 months ago
📢 Starter Kit Update
5 months agoHello everyone! A quick heads up about an important stability update to the starter kit.
We’ve migrated the transport/communication backend (previously based on MCP/FastMCP) to gRPC to make the interaction between your agent and the game environment more robust and predictable .
What changed?
- The underlying transport layer is now gRPC-based .
- The agent-facing interface and APIs are unchanged . Your existing agent code should continue to work as is.
- The main goal of this change is better resilience under long games and reconnections .
Why this matters?
Some of you were seeing:
- Random stalls / timeouts during longer runs
- Reconnection issues
- Episodes hanging with no clear error
These issues were caused by how requests were queued and retried in the previous MCP-based setup. With gRPC, we now strictly enforce “one client, one action in flight” , and we get clearer error handling, which should eliminate these stalls and make reconnect behavior much more reliable.
What you need to do
-
Update your local starter kit
- Pull the latest changes from the repo (e.g.,
git pull --rebase).
- Pull the latest changes from the repo (e.g.,
-
Reinstall/refresh dependencies if needed
uv sync
-
Run your existing agents as usual
- No changes should be required to your agent logic or environment interaction code.
If you still see issues
If you run into:
- Timeouts
- Stalls
- Reconnection problems
please share:
- Logs (client + server, if possible)
- Approximate episode length and map
- Steps to reproduce
This will help us quickly track down any remaining edge cases.
Thanks for your patience while we tracked this down.
StarCraft Stuck After Episode 1 (‘Client is not connected’ Issue)
5 months agoWe use the Linux headless binary for evaluations, and the steps below should help you get everything set up clearly:
- Download the last available version (4.10) from GitHub - Blizzard/s2client-proto: StarCraft II Client - protocol definitions used to communicate with StarCraft II..
- Check the README for instructions on unzipping the archive. It’s password protected, and the password is provided in the README itself.
- Extract the game into your
$HOMEdirectory. After extraction, the expected path should be$HOME/StarCraftII. - Depending on your
burnysc2version, the maps directory may need to be either$HOME/StarCraftII/Mapsor$HOME/StarCraftII/maps. To avoid issues with missing map directories, create a symlink:ln -s $HOME/StarCraftII/Maps $HOME/StarCraftII/maps - For additional details on configuring the maps, see: Question about SC2 map setting in starter kit
Model submission
5 months ago- The final evaluations would be manually run by Krafton AI team and the prizes would be decided based on the outcome of the manual runs. Krafton AI team would verify the size of the model you submit during the final evaluations.
- No, we do not require any sort of access to your LLM server. However, for the final evaluations, you would need to include precise instructions and code that is needed to start your LLM server and ensure that Krafton AI team is able to run everything end-to-end.
Model submission
5 months agoNo, it doesn’t need to be hosted externally. We simply provide the endpoints that let you get game observations, and your agent only needs to return the actions to execute in the game. How you produce those actions whether through local models, external services, or any other setup is entirely up to you.
This means your machine must be able to access whichever models or services you rely on during inference.
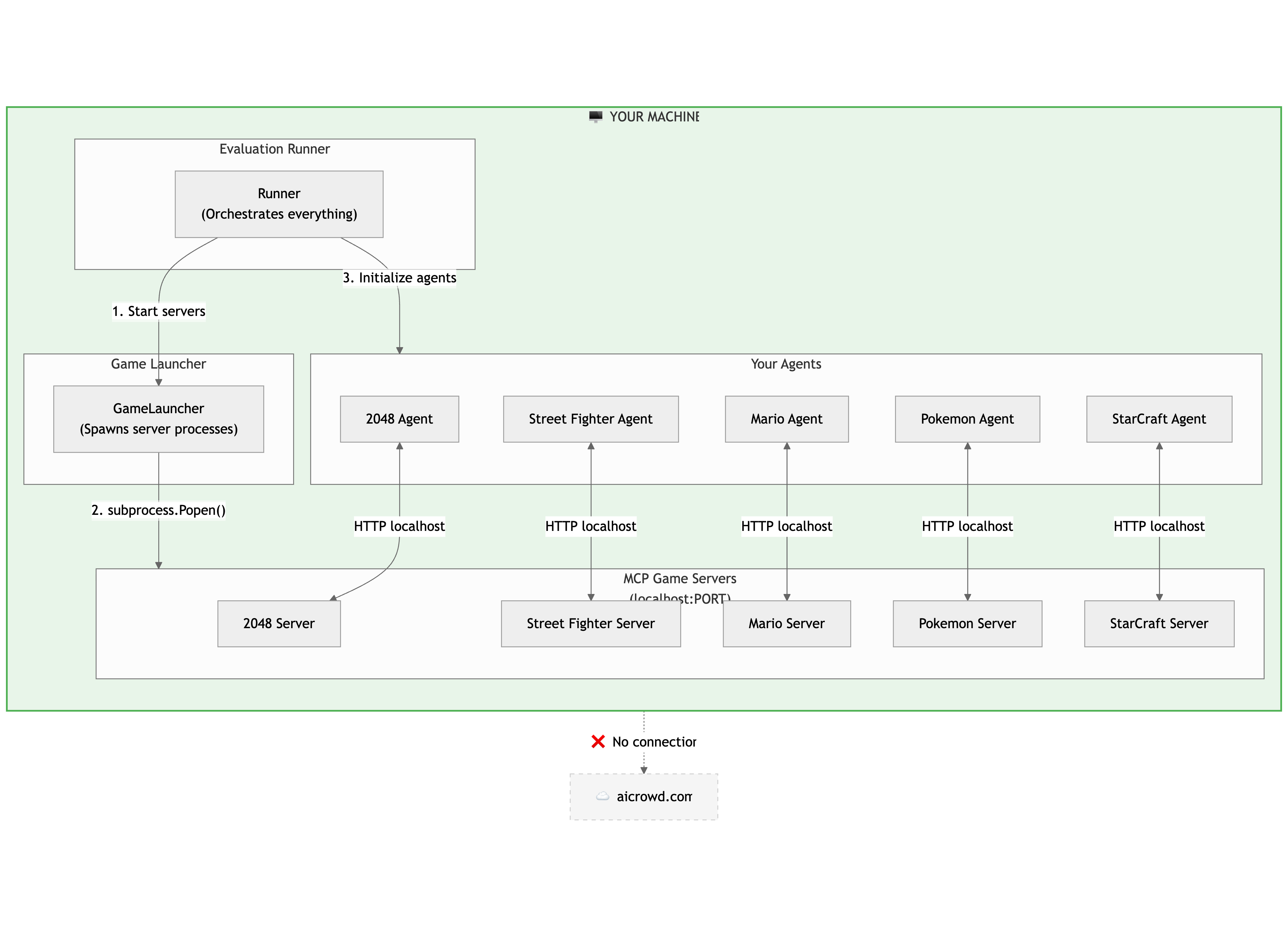
In Local Mode, everything (your runner, game launcher, agents, and the MCP game servers) runs directly on your machine. The runner starts the game servers, initializes your agents, and your agents communicate with the servers over localhost. There is no connection to the AIcrowd backend.
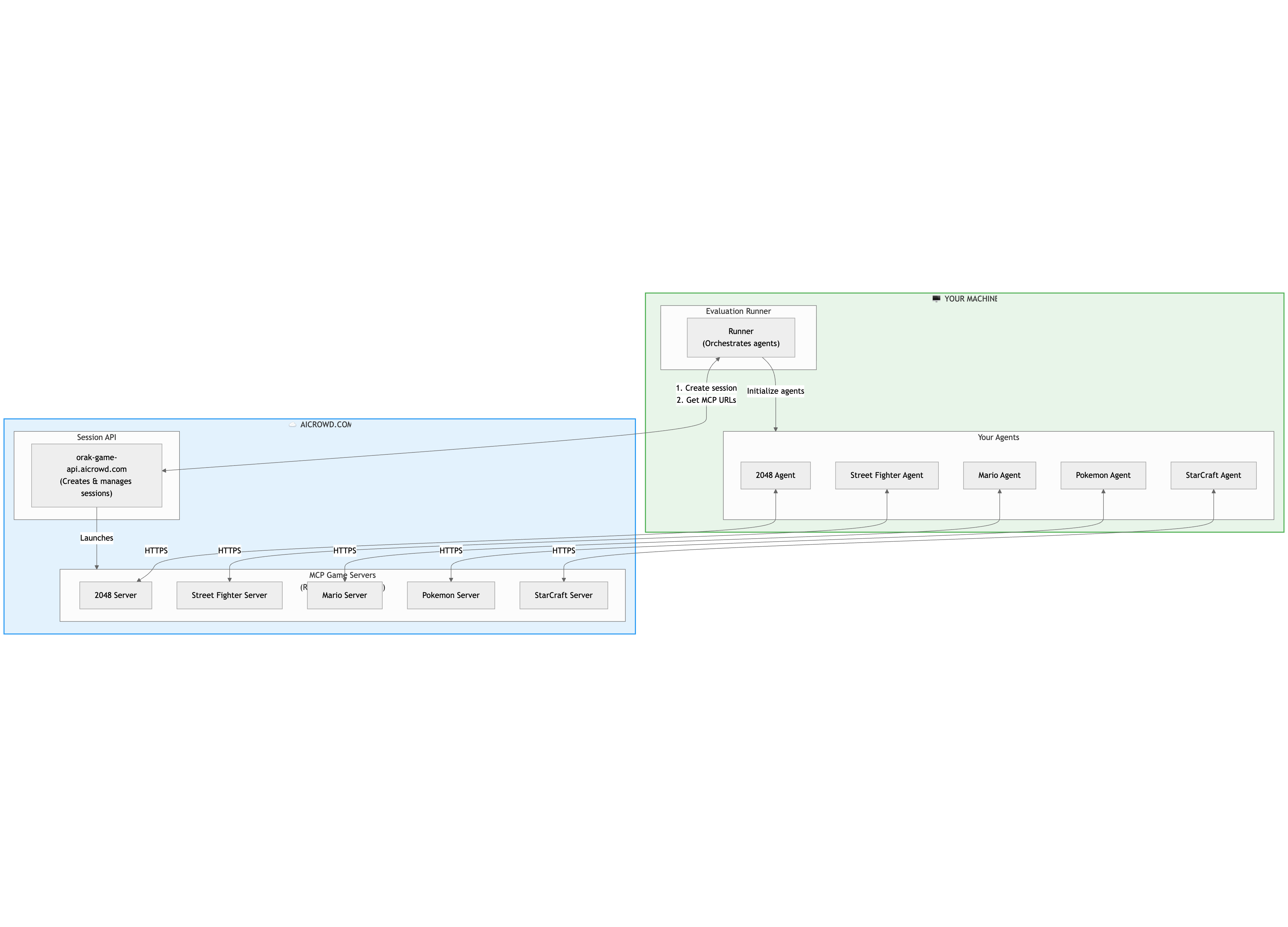
In Remote Mode, your runner and agents (including the LLM calls you make etc.,) still run locally, but the MCP game servers run on AIcrowd’s remote infrastructure. Your runner creates a session via the Session API, receives the MCP server URLs, and your agents interact with the remote servers over HTTPS.
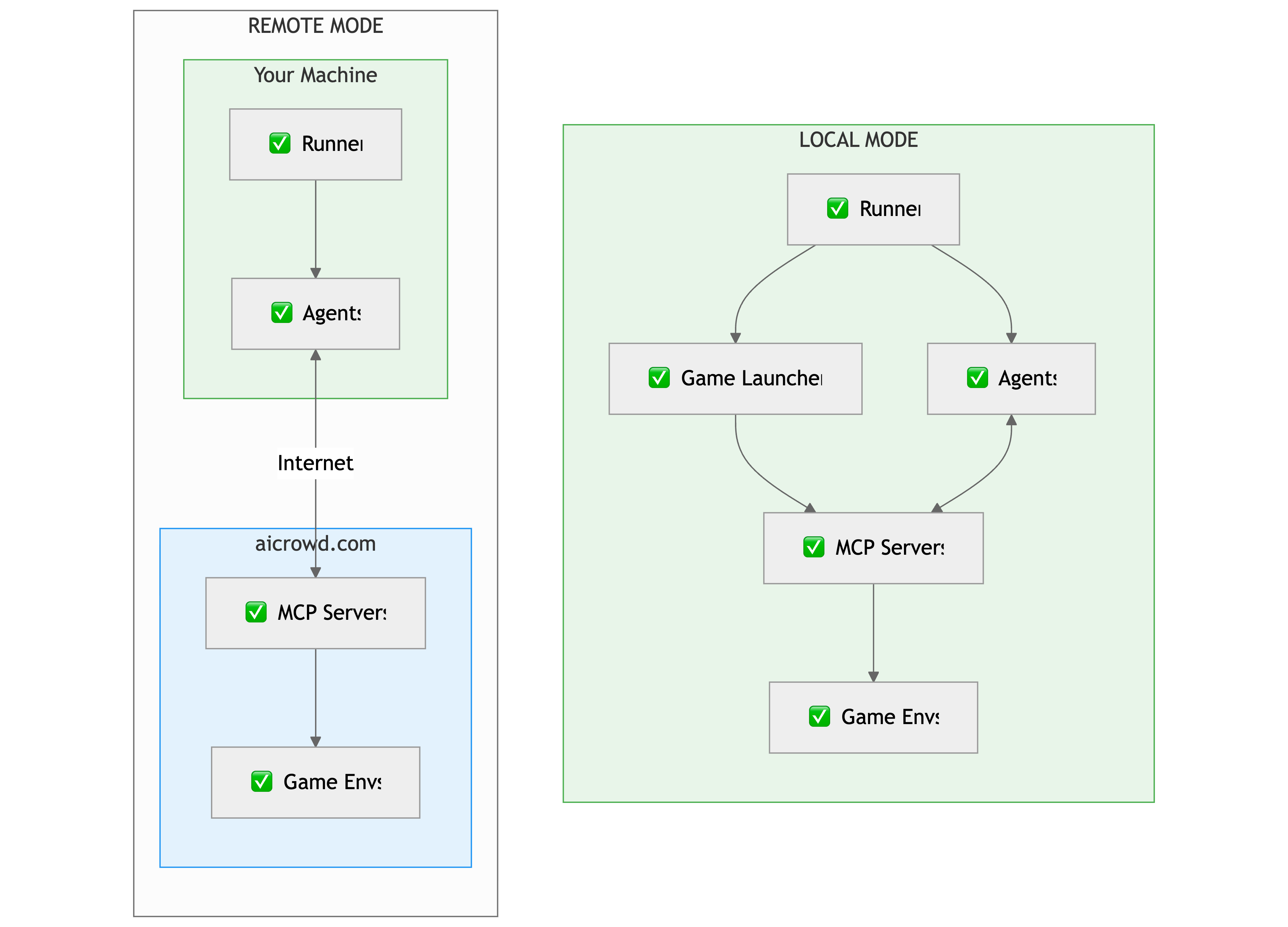
- Local Mode hosts the entire stack on your machine.
- Remote Mode keeps your agents local while offloading the game servers and environments to AIcrowd.
Hope this makes it clear
ModuleNotFoundError: No module named 'omegaconf'
5 months agouv looks for pyproject.toml and automatically manages the virtual environment at the repo level.
Can you verify that your environment is actually being used?
# check which Python uv is running
uv run python
# try importing a starter-kit–specific library, for example:
import sc2
If this import works, then uv is configured correctly.
You can install additional packages with:
uv add <package>
Although uv pip install -r pyproject.toml works, it’s generally better to use:
uv sync
This installs the exact dependency versions listed in uv.lock, matching the environment used during starter-kit testing.
Model submission
5 months agoYou don’t need to submit your model directly for this challenge. When you make a submission, we automatically launch an instance of each game and provide your agent with a unique MCP address for that run. Each game reports its score back to us, and we update the leaderboard accordingly.
Global Chess Challenge 2025
Submissions stuck at "Compiling model for Neuron"
5 months ago@artist @whoamananand it seems like the models are hitting memory limits. Can you share the the config params you used to compile the model on trn1.2xlarge so that we can investigate this further?
Submitting models to Neuron: pick the right `--neuron.model-type` (and tune vLLM if you need to)
5 months agoHey @whoamananand
Your model is hitting memory limits and crashing the node on which the evaluation was running. Can you try submitting a smaller model?
We will figure out a way to relay the OOM errors properly on the submission details page.
Submitting models to Neuron: pick the right `--neuron.model-type` (and tune vLLM if you need to)
5 months agoWhen you run aicrowd submit-model, the platform spins up a vLLM server for your model. You can pass a handful of --vllm.* flags to control things like max context length, dtype, batching limits, LoRA settings, and a few inference-time parameters.
But there’s one flag you must get right for Neuron hardware:
--neuron.model-type <model-type>
Why this matters (Neuron compilation in one paragraph)
AWS Inferentia/Trainium (Neuron) doesn’t run your PyTorch model “as-is” the way a typical GPU setup might. The model needs to be compiled into a Neuron-compatible artifact before it can run on the accelerator.
Because the compilation path is model-architecture-specific, the submission system needs to know which backend/architecture you’re using. Hence --neuron.model-type.
If you don’t set --neuron.model-type, the submission will default to qwen3.
Supported model types (backends)
The NxD Inference model hub currently supports architectures including: Llama (text), Llama (multimodal), Llama4, Mixtral, DBRX, Qwen2.5, Qwen3, and FLUX.1 (beta).
(For the others, the exact string is typically the obvious lowercase name, aligned to the supported architecture list above. If you’re unsure, match it to your model family—e.g., Mixtral → mixtral, Qwen3 → qwen3—because picking the wrong type can lead to compile failures or incorrect behavior.)
Supported vLLM server flags
aicrowd submit-model currently supports these vLLM arguments:
--vllm.max-model-len
--vllm.dtype
--vllm.kv-cache-dtype
--vllm.quantization
--vllm.load-format
--vllm.rope-theta
--vllm.rope-scaling
--vllm.max-num-batched-tokens
--vllm.max-num-seqs
--vllm.enforce-eager true
--vllm.enable-lora true
--vllm.lora-dtype
--vllm.lora-extra-vocab-size
--vllm.enable-prefix-caching true
--vllm-env.allow-long-max-model-len
# inference time parameters
--vllm-inference.max-tokens
Example: complete submission command
At minimum, set your repo/tag and the Neuron model type:
aicrowd submit-model \
--hf-repo <repo> \
--hf-repo-tag <branch/tag> \
--neuron.model-type llama
Or, for DBRX:
aicrowd submit-model \
--hf-repo <repo> \
--hf-repo-tag <branch/tag> \
--neuron.model-type dbrx
If you need tighter control over serving behavior, add the relevant --vllm.* flags on the same command.
Concerns About Challenge Readiness - Seeking Clarification
5 months agoHello @sankar_ram
- We are already accepting submissions. In an unlikely case that there are any more changes to the evaluation setup, we will re-evaluate the submissions as needed. You can start submitting your models right away.
- As of now, you can make 5 submissions per day.
- “Global Chess Challenge” is the name of the competition. “AWS Trainium Challenge 2025” was a placeholder we used during our internal development.
Notebooks
-
 Solution for submission 128368 A detailed solution for submission 128368 submitted for challenge IIT-M RL-ASSIGNMENT-2-TAXIjyotish· About 5 years ago
Solution for submission 128368 A detailed solution for submission 128368 submitted for challenge IIT-M RL-ASSIGNMENT-2-TAXIjyotish· About 5 years ago -
 [Baseline] Detectron2 starter kit for food recognition 🍕 A beginner friendly notebook kick start your instance segmentation skills with detectron2jyotish· Over 5 years ago
[Baseline] Detectron2 starter kit for food recognition 🍕 A beginner friendly notebook kick start your instance segmentation skills with detectron2jyotish· Over 5 years ago
Intermittent UNAUTHENTICATED: Session expired (timeout: 120s) across all games (local + remote)
5 months agoThe sessions are ideally supposed to reauthenticate and continue normally. Can you share with us some script using which we can reproduce this error?